你是否在原始文本上进行RAG模型的预训练?
检索增强生成(RAG)通过对原始文本进行有针对性的预训练,在许多方面都有显著提升。目前,只有ThirdAI的NeuralDB能够在插入过程中为任何文本提供一键式的预训练和/或微调功能。
RAG目前是在任何特定的文本集合上创建可靠且经过验证的基于AI的代理的最可靠和成熟技术。如果想要更多了解RAG以及如何构建无幻觉AI代理,请查看我们之前的博客文章。在本文中,我们将重点讨论检索质量以及在可用文本语料库上进行预训练模型的重要性,该语料库目前仅用于索引。
一个常见的误解是,使用一个“足够好”的预训练基础模型来生成嵌入向量,并在向量数据库中进行检索是足够的。然而,这种误解现在正受到广泛挑战。像谷歌的T5或OpenAI的Ada这样的知名模型在与专门调整用于检索任务的更简单的模型相比,很难实现高精度。
越来越多的案例研究出现,强调选择正确的嵌入模型的重要影响,而且没有通用的解决方案。如果企业认为定制嵌入模型和进一步优化很少需要,那么他们只是延迟了无可避免的现实检验。搜索是一项基本具有挑战性的任务,特别是在规模较大的情况下,可能有多个相关但不相关的信息。即使经过十多年的研究,我们所知道的所有流行的语义搜索系统,包括谷歌和亚马逊的系统,都需要经常进行微调和重新训练,以适应行为和领域相关的变化。
如果您没有为任务定制嵌入模型,那么很可能您无法获得最佳准确性。
保持HTML结构,请将以下英文文本翻译成简体中文: 有两种方法可以将嵌入或神经模型专门应用于领域相关的检索——1. 在目标文本上进行自监督预训练,2. 使用监督行为数据进行微调。我们将简要描述这两种方法,然后解释为什么它们都是必要的。
什么是原始文本的自监督预训练,以及为什么它有助于RAG?一个在普通英语中表现良好的模型仍然需要进行微调,以在企业数据领域卓越。对于任何文本语料库,我们可以为训练神经网络定义一个自然的“辅助任务”。在这些“辅助任务”上进行训练可以改进神经网络对文本的内部表示,使其专门适用于特定领域。其中最受欢迎的任务之一是通过优化下一个单词预测来改善模型的权重,这是一种广泛使用的生成任务。应用于特定领域的文本时,下一个单词预测可以带来显著的改进(见下面的实验)。另一个普遍存在的自监督任务涉及利用两个连续的句子来微调神经网络的表示,目的是将其余弦相似度与非连续句子进行最小化对比。
什么是RAG中的有监督微调,以及为什么它对于语义搜索是必要的?众所周知,如果缺乏行为数据和持续的工程化,语义搜索无法变得实用。例如,当我们输入“apple login”时,我们的意图是登录到苹果账户。仅依靠语义意义会导致大量关于登录苹果的常见问题和信息页面的出现,即使我们并不打算访问这些页面。信息检索界承认,只有过去的行为数据才能准确捕捉意图。如果没有这些行为信号,仅仅基于文本和其结构的语义搜索很难使用。实际上,“语义”这个术语是设计用来涵盖“用户意图”而不仅仅是英语理解。因此,不足为奇的是,大多数基于GenAI模型的表示对于“语义搜索”来说是不可用的。
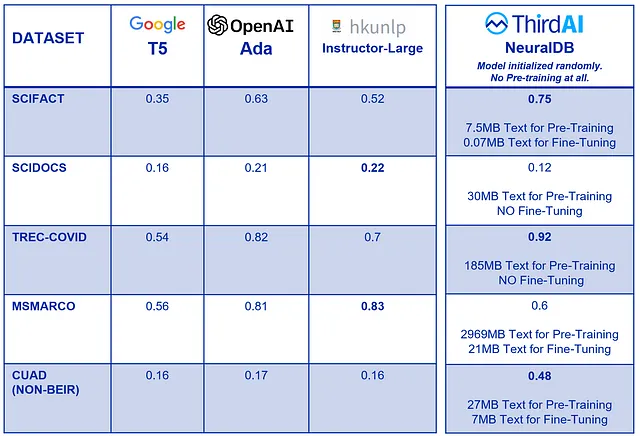
一个随机初始化的NeuralDB模型,在进行了少量的预训练和微调之后,击败了流行的Foundation Models!
我们选择了不同大小的知名BEIR基准数据集(两个小的和两个大的),其中包括了用于检索目的的标准评估集。我们使用了三种流行的基础嵌入方法作为RAG的参考基准进行评估:1. Google的T5,2. Instructor-Large和3. OpenAI的Ada。由于其标准基准地位,这些基础模型在一定程度上对BEIR有所偏见。因此,此外,我们还包括了CUAD数据集,该数据集衍生自涉及合同审查的真实业务场景。所有这些数据集都包含一个测试集。
为了突出RAG中预训练的重要性,我们进行了一项极端实验。我们将ThirdAI的NeuralDB模型专门在索引的文本语料库上进行了预训练。如果有数据可用,我们还会进行微调。实质上,NeuralDB只能从索引的文本中学习,完全没有接触到任何其他文本。相比之下,流行的基础模型在数百GB到TB级别的文本上进行了广泛的预训练。与当前的观点相反,我们发现只需几分钟的领域特定预训练,NeuralDB的性能就可以超过这些基础模型。
结果令人惊讶,并总结在下表中:
为什么这个观察被忽视了?这样的实验之所以罕见,是因为预训练通常被认为是专家的任务,仅限于复杂的数据科学和工程团队。然而,有了NeuralDB,预训练和微调都变得非常容易。您只需要在索引插入过程中设置一个标志为“true”,然后经过几分钟,您就可以获得预训练于指定文本的检索模型。有关如何简便地进行预训练和复制以下实验的详细说明,请参阅本笔记本。任何人都可以使用简单的CPU对任何文本语料库进行预训练和/或微调NeuralDB模型。
预训练的数量重要吗?似乎并不重要。数据集的文本量变化很大。例如,SCIFACT数据只包含约7.5兆字节的文本。NeuralDB只是从一些领域特定的文本中完全无监督地预训练,仅使用了几兆字节的文本,但它仍然优于所有的基础模型。
合同审查AI代理(真实案例):预训练和微调至关重要!基于一个真实客户的需求,创建一款实用的合同审查和法律问答AI代理,我们分享了我们的成果。我们使用了全面的CUAD数据集,该数据集专为合同相关的检索增强生成(RAG)任务设计,提供真实世界的背景。通过专注于领域特定的训练和优化,NeuralDB以较大的优势显著超越了基础模型。
此外,结果还凸显了开源基础模型对已建立的BEIR基准的固有偏见。当涉及到非BEIR基准时,与令人印象深刻的相对较少努力所能取得的优秀结果相比,基础模型似乎明显不如。毫不奇怪,所有三个基础模型似乎都获得了类似(糟糕的)准确性。
讨论:一篇ICML 2023论文给出了一些启示。
最近在ICML 2023会议上发表的一篇论文,题为《大型语言模型在学习长尾知识上存在困难》,有效地呼应了我们的观察。这项研究的全面实验表明,无论语言模型的规模大小,当其缺乏与任务相关的数据暴露时,其性能都会下降。引用摘要中的一句话:“具体来说,我们的研究表明,语言模型回答事实性问题的能力取决于其在初始训练期间看到的与该问题相关联的文档数量。”
显然,通过仅在用于索引的文本上进行预训练,我们为模型提供了比花费数月在千兆字节的数据上进行昂贵预训练更多相关的信息。
底线
目前,对基础模型进行微调和预训练以使其具备功能仍然是企业面临的一个重大挑战。由于持续存在的显卡短缺和模型调优所需的专业知识,这个任务在不久的将来不太可能变得更加容易。我们很高兴地宣布,ThirdAI的NeuralDB现在对每个人都可用。有了NeuralDB,您可以利用您的所有文本,无论是通过预训练和/或微调,而不需要等待显卡或组建专家团队。
以您所需的方式塑造您自己的 AI。无需受硬件或人力限制,根据您的需要调整其规模。未来已经来临!