LLMs的组成部分(速成课程:第一部分)
部分1:预训练语料库和预处理
本文的视频形式也可以在以下链接观看:https://www.youtube.com/watch?v=bee1cIl7Y8w

在这个视频中,我将为您提供先进的大型语言模型(LLMs)中存在的主要组成部分的概述。这个第一章将重点讲解为预训练过程收集和准备数据的过程。

LLMs通常首先在一个大型和通用的数据集上进行无监督目标的预训练,然后针对给定的任务、目的或领域进行一定形式的微调,以便应用到它们身上。
考虑到预训练语料通常是模型的初始先验条件,关于这一主题开始本视频是很自然的。
尽管多模态开始受到一些关注,但迄今为止,特别限定在文本领域的大型模型,即LLMs,一直是研究者的首要选择。
预训练语料库:
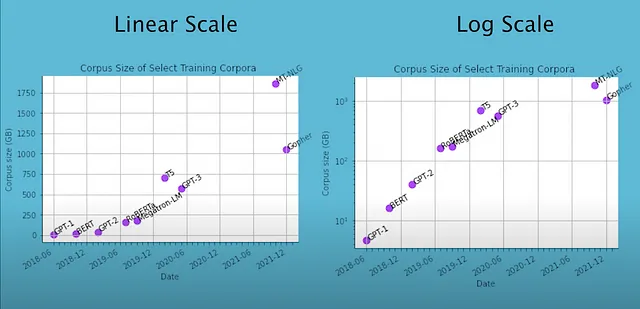
这些图表展示了一些知名的LLM以及它们对应的预训练语料库大小。2021年的LLM,例如Megatron Turing-NLG和Gopher,是在超过一兆字节大小的语料库上进行训练的。
这样大规模的数据集从哪里来呢?
鉴于LLM预训练的目标是产生语言的通用表示,而语言理想上是对世界的一种表达,研究人员已经从多样化、广泛的来源中选择了被认为是高质量的语料库。
“高质量”的含义是由研究者决定的,但通常意味着由事实、准确和逻辑严谨的陈述构成,在性别、种族或文化偏见方面具有多样性,不包含个人信息,内容涵盖广泛,同时还包括研究者希望在模型中注入的其他特征。
提供给模型的信息直接决定了它将会成为什么样的东西。我会在视频的训练部分详细介绍这个概念。
接下来,我将提供更多具体的例子,说明这些语料库中包含的数据以及它们随时间的发展情况。

保留HTML结构,将以下英文文本翻译成简体中文: GPT-1和BERT在2018年下半年引爆了LLM热潮——它们分别是通过一系列未发布的书籍进行训练,BERT还使用维基百科进行了训练。
2019年,RoBERTA和GPT-2语料库包括新闻文章和一些公共网站,尤其是Reddit。这些网站通过启发式方法进行了质量筛选,比如根据点赞数目。
2019年末,研究人员所搜索的个别网站数量急剧增加,因为大规模的全网抓取数据集开始被创建或变得流行。这些来源包括各种学术网站,如科学期刊、代码仓库、教育网站等等。同时,可以访问社交媒体对话和对话数据的公司也开始利用这些资源。
快进到2021年,尽管语料库通常超过一兆字节,并且始终期望更好质量的数据,但预训练数据集的大小尚未成为一个主要的限制因素。迄今为止,LLMs总是被训练一个时期,当进行多个时期的训练时,表现更差,即使使用更多的计算资源。
预处理:
一旦预训练语料库被定义和准备好,那些数据需要被准备和转换成一种模型既可以处理它,也能最好地学习来表示它的格式。

第一步是清洁。例如,删除重复内容,删除网站HTML标签或其他结构化的非内容文本,删除意外出现的字符等等。
经过清洗之后,有时候会进行停用词去除、词形归并和词嵌入转换。停用词是在句子中可能没有或几乎没有意义的词,例如“a”、"an"、"the"等。词形归并是将词语缩减为其基本形式,例如将“running”缩减为“run”。词嵌入转换是将每个词语转换为由另一个模型或算法提供的嵌入。
虽然这3种技术在自然语言处理中历史上很流行,但它们似乎正在逐渐被淘汰,最近的模型很少或根本不使用这些技术。
最后,将文本编码为将被输入模型的令牌。这些令牌通常不是单个字符,也不是单个词语,而是介于两者之间的某种形式。
为什么?
尽管由单个字符组成的标记缺乏词中顺序字符或词的部分所含的大部分信息或内在意义。模型可以隐式地学习这些意义,但是标记化可以以一种明确地帮助模型完成这个任务的方式进行。此外,进一步阻碍字符级标记化的事实是,标记越小,输入的总标记数就越多,因此计算成本就越大。
所以这就是为什么字符级标记化不理想,那么词级标记化呢?
当然,将整个单词输入模型也可以提供超出个别字符的上下文,然而模型需要一个固定的词汇量大小——当模型输出一个标记时,它是从一个词汇表中选择的。词汇表越广泛,选择的挑战可能变得更大。任何现代语言很可能有成千上万个单词。
此外,这不仅仅是关于技术限制 - 将一个单词分成子集通常可以通过语言结构更清晰地表达单词的含义 - 例如:心理-学,"心理" 意味着 "心智,精神" 而 "-学" 意味着 "研究"。

最流行的编码算法之一被称为字节对编码,或BPE。
BPE 是一种贪婪算法,通常会输入一个目标词汇大小,然后迭代地合并来源语料中最常出现的字符对,直到达到目标词汇大小。
让我们通过一个示例来看看它是如何工作的。给定语料库: 苹果,香蕉,蔓越莓和杏子。

在第1次迭代中,我们查看我们的语料库,发现‘an’出现了3次,并且是最频繁出现的组合,所以我们将它们合并,然后更新我们的词汇表:

现在进行第二次迭代,我们观察到ap出现了两次,并且现在成为了最频繁出现的一对,因此它们被合并,我们的新词汇表是:

可用于BPE的替代停止条件包括词汇大小的要求,而在这个简单示例中,我将停止,因为没有其他频率大于1的配对。
除了终止条件之外,BPE还可以通过许多其他方式进行修改。其他编码算法如WordPiece编码和SentencePiece编码通过引入附加功能和灵活性来扩展BPE,可以更好地构建用于多语言词汇或不同文本类型和特征的编码。
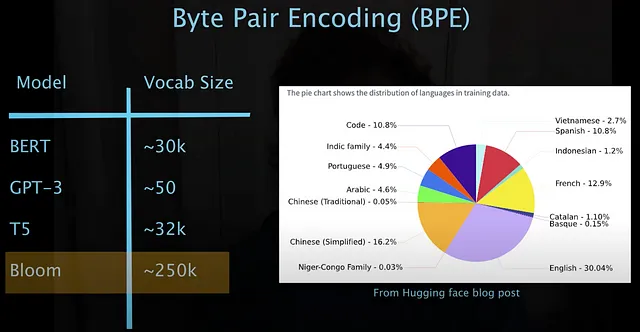
BPE有许多变体,用于更好地构建编码,如多语言词汇或不同文本类型和特征的目的。例如,代表更多语言的模型在其词汇表中自然会有更多的标记。
这就是第一部分的内容,希望你有所收获。我们非常欢迎任何反馈。
接下来,在第二部分中,模型架构: