精细调整OpenAI LLM模型
ChatGPT正在成为当今技术驱动世界中不可或缺的工具。它被广泛应用于语言翻译、聊天机器人服务和写作帮助等任务。无论是通过UI还是API使用,它都作为多种应用的通用工具。
除了ChatGPT之外,OpenAI还有很多选项,比如语言模型(LLM),它非常适用于自然语言处理任务。另一个优势是能够使用您的数据对这些模型进行微调,为各种NLP需求提供可定制的解决方案。
在本文中,我们将深入探讨微调情感分类模型的具体细节。对于不熟悉OpenAI API的读者,我们建议先阅读我们之前的综合指南,以帮助您入门。
我们将使用ACL 2011年论文[1]中的电影评论数据集进行练习。这些数据作为微调二元情感分类模型的基础,有效地训练模型理解积极和消极的情感。
在开始之前,请确保安装了OpenAI软件包并设置了API密钥。此步骤对于推进过程至关重要。
!pip install --upgrade openai --quiet
import openai
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"数据结构包含两个重要组件:“文本”用于存放电影评论,“标签”用于标记情感是“pos”还是“neg”。我们将主要关注这些内容,但让我们将它们重命名为“提示”和“完成”,以更好地适应我们的上下文。
df.head()
接下来,我们要添加分隔符。这些分隔符作为标记,用于区分提示结束的位置和完成开始的位置。在我们的场景中,我们会在每个提示的末尾添加'\n\n###\n\n',在每个完成的开头添加一个空格。
def add_strings_in_the_end(df,col,add_str):
df[col]=df.apply(lambda x: x[col] + add_str,axis=1)
return df
def add_strings_in_the_begining(df,col,add_str):
df[col]=df.apply(lambda x: add_str+x[col],axis=1)
return df
df=df[['text','tag']]
df=df.rename(columns={'text':"prompt"}).rename(columns={'tag':"completion"})
df=add_strings_in_the_end(df,'prompt', '\n\n###\n\n')
df=add_strings_in_the_begining(df,'completion', ' ')一旦我们的数据整理好了,我们将把它转换成一个json文件,并使用'fine_tunes.prepare_data'。 这个函数是openai软件包提供的,它会验证和纠正数据。 它还足够聪明,能够确定我们是否正在处理分类问题,甚至处理训练-测试拆分。
train.to_json("train.jsonl", orient='records', lines=True)
!openai tools fine_tunes.prepare_data -f train.jsonl -q
Analyzing...
- Your file contains 320 prompt-completion pairs
- Based on your data it seems like you're trying to fine-tune a model for classification
- For classification, we recommend you try one of the faster and cheaper models, such as `ada`
- For classification, you can estimate the expected model performance by keeping a held out dataset, which is not used for training
- All prompts end with suffix `\n\n###\n\n`
No remediations found.
- [Recommended] Would you like to split into training and validation set? [Y/n]: Y
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
Wrote modified files to `train_prepared_train.jsonl` and `train_prepared_valid.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "train_prepared_train.jsonl" -v "train_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " pos"
After you’ve fine-tuned a model, remember that your prompt has to end with the indicator string `\n\n###\n\n` for the model to start generating completions, rather than continuing with the prompt.
Once your model starts training, it'll approximately take 10.01 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.当我们的数据准备好后,我们使用“fine_tunes.create”开始训练。在这个微调过程中,它会生成一个独特的‘ft-xxxxxxxxxxxx’ ID。您可以使用“fine_tunes.follow”跟踪您的模型进度,提供有关队列状态、时代进度和微调成本的更新。训练完成后,它会提供模型名称,通常包括模型类型、组织名称和日期。
!openai api fine_tunes.create -t "train_prepared_train.jsonl" -v "train_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " pos" -m ada
openai api fine_tunes.follow -i ft-xxxxxxxxxxxxx
[2023-06-04 23:21:59] Created fine-tune: ft-xxxxxxxxxxxx
[2023-06-04 23:23:18] Fine-tune costs $0.01
[2023-06-04 23:23:19] Fine-tune enqueued. Queue number: 0
[2023-06-04 23:33:22] Fine-tune started
[2023-06-04 23:34:17] Completed epoch 1/4
[2023-06-04 23:34:59] Completed epoch 2/4
[2023-06-04 23:35:39] Completed epoch 3/4
[2023-06-04 23:36:20] Completed epoch 4/4
[2023-06-04 23:36:45] Uploaded model: ada:ft-your-organization-xxxx-xx-xx-xx-xx-xx
[2023-06-04 23:36:47] Uploaded result file: file-xxxxxxxxxxxxxxxxxxx
[2023-06-04 23:36:47] Fine-tune succeeded
Job complete! Status: succeeded ?
Try out your fine-tuned model:
openai api completions.create -m ada:ft-your-organization-xxxx-xx-xx-xx-xx-xx -p <YOUR_PROMPT>随着模型训练并准备就绪,您可以开始使用微调模型进行推理。
frac_model = 'ada:ft-your-organization-xxxx-xx-xx-xx-xx-xx'
sample_input="in fact , the scene stealer is simon's dog , who is funnier than nicholson ."
res = openai.Completion.create(model=frac_model, prompt=sample_input + '\n\n###\n\n', max_tokens=100, temperature=0, stop=['\n'])
res['choices'][0]['text']
' pos'
sample_input="as the movie is but the latest in a genre that was originally created by aliens , it does little more than try to cash in on that aspect ."
res = openai.Completion.create(model=frac_model, prompt=sample_input + '\n\n###\n\n', max_tokens=100, temperature=0, stop=['\n'])
res['choices'][0]['text']
' neg'目前,OpenAI提供了五个模型进行微调:ada、babbage、curie、davinci和text_davinci_002。每个模型都有各自的优点和缺点,在准确性、训练成本和推理成本方面也各不相同。是的,微调的模型还有推理成本。欢迎尝试不同的模型以评估它们的性能。
!openai api fine_tunes.create -t "train_prepared_train.jsonl" -v "train_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " pos" -m davinci另外,您现有模型可以持续进行微调。默认情况下,epoch 数量设定为四,但可以根据您的需求进行调整。图[2]呈现了模型表现相对于数据大小和epoch数量的基准。此参考资料认为相对于数据大小有最佳的epoch数量。
!openai api fine_tunes.create -t "train_prepared_train.jsonl" -v "train_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " pos" -m ada:ft-your-organization-xxxx-xx-xx-xx-xx-xx --n_epochs 16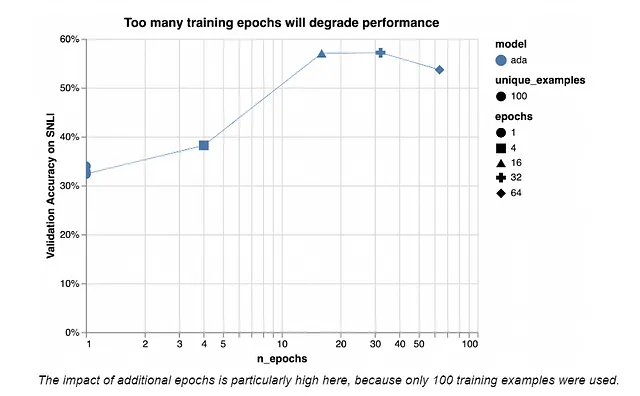
参考文献:
[1] Maas, Andrew L.、Daly, Raymond E.、Pham, Peter T.、Huang, Dan、Ng, Andrew Y. 和 Potts, Christopher。Learning Word Vectors for Sentiment Analysis,{Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies},2011 年 6 月。
[2] GPT-3细调文本分类的最佳实践,https://docs.google.com/document/d/1rqj7dkuvl7Byd5KQPUJRxc19BJt8wo0yHNwK84KfU3Q/edit#heading=h.86jb439egjbi