AI背后的“力量”
强化学习反馈飞轮循环

两天前,我们重点关注了亚马逊的杰夫·贝佐斯(Jeff Bezos)如何利用如今著名的亚马逊飞轮(Amazon Flywheel)将一个建议的业务战略变成了价值超过万亿美元的企业。昨天,我们看到了OpenAI与合作伙伴微软合作,通过其基金会大型语言模型人工智能(LLM AI GPT3、GPT 4等)和极其成功的ChatGPT应用程序和客户端开始在规模上实现其自己的飞轮,并且谷歌、Meta和其他竞争对手也在做同样的事情。
但是,AI周期中有一类完全不同的飞轮回路,我想在这里进行审查。它们被称为人类反馈强化学习(RLHF)和AI反馈强化学习(RLAIF)回路。我知道这很啰嗦,但它们在使 AI 成为酷炫但仍需包容错误的软件和 AI 成为潜在“神奇”和超越人类的软件方面有着重大的区别。让我解释一下。
正如“AI Native”公司Weights&Biases所解释的那样:
随着AI模型不断增长,偏见、公平性和安全问题浮现。从人类反馈中进行强化学习(RLHF)是一种新方法,用于减少大型语言模型(LLM)的偏见。
在本文中,我们探讨如何使用RLHF来减少LLMs中的偏见,提高性能、公平性和代表性。
“在这里的核心目标是让传统的大型语言模型(我们的案例中是GPT-3)与人类原则或偏好相一致。这使得我们的LLM更少有毒性,更真实,更少带偏见。”
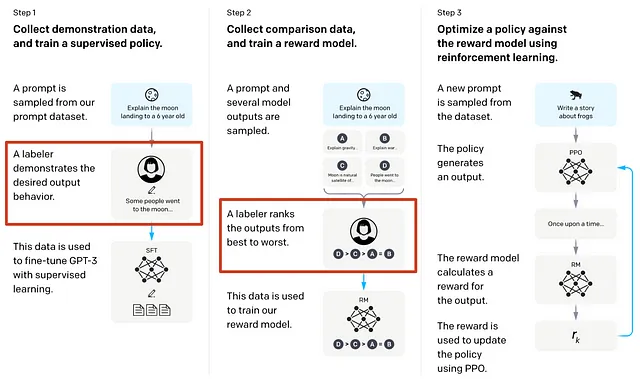
以下图表更详细地解释了该过程。它包括几个关键步骤:
- 从维基百科、Reddit、谷歌图书、学术论文数据库、媒体网站(经授权)等网站上提取数据,使用网络爬虫软件。
- 然后利用人类和机器的“标记员”来筛选、处理和优化提取的数据。
- 然后运行人工和机器生成的提示,测试数据输出与LLM AI模型的相符程度。
- 然后将这些查询的输出从最好到最差排名。
- 使用结果再次训练底层模型,以提高精度和消除偏差。根据需要重复、清洗和运行强化学习循环。
- 继续使用各种额外技术对这些结果进行规模化优化。正如上面提到的,这需要通过人类和人工智能机制使用强化学习技术。
自去年11月底ChatGPT推出以来,人工智能研究人员对这些强化学习(RL)循环如何从根本上提高LLM AI模型的可靠性和实用性感到惊讶。正如斯坦福开源LLM AI团队的一位高级研究员告诉我,“这个过程通过将初始模型结果中最差的20%提高80%或更多来大大增强这些模型的功效”。
研究人员发现优化创新才刚刚开始。新老的AI公司都专注于改进和加强这些模型,不论是在LLM AI过程的训练还是学习周期中。
关键在于这些RLHF和RLAIF循环创造的惯性转轮越来越会负责“紧急”的“人工通用智能(AGI或超级智能)”,正如微软研究员最近的一篇人工智能论文中所讨论的那样,LLM人工智能开始表现出来。
RLHF 的其他好处包括:
“RLHF在ChatGPT和GPT-4等AI系统的开发中提供了多种优势:”
- 提高性能:通过将人类反馈纳入学习过程中,RLHF 帮助 AI 系统更好地理解复杂的人类偏好,并产生更准确、连贯和上下文相关的响应。
- 适应性:RLHF 使得 AI 模型能够通过从人类训练者的多样化经验和专业知识中学习,从而适应不同的任务和情境。这种灵活性使得这些模型能够在各种应用中表现良好,从对话型 AI 到内容生成,以及更多。
- 降低偏见:迭代的反馈收集和模型重新调整过程有助于解决和减轻最初训练数据中存在的偏见。随着人类培训师评估和对模型生成的输出排名,他们可以识别和解决不良行为,确保 AI 系统更符合人类价值观。
- 持续改进:RLHF 过程可以使模型性能持续改进。随着人类训练员提供更多反馈和模型经过强化学习,它变得越来越擅长生成高质量的输出。
- 增强安全性:RLHF通过允许人类训练者将模型从生成有害或非预期内容的方向引开,有助于开发更安全的人工智能系统。这种反馈循环有助于确保人工智能系统在与用户交互时更加可靠和值得信赖。
当AI Analytics Vidhya的这些人突出强调RLAIF比RLHF的日益重要性时:
我们可以使用不同的LLM AI模型大小,在不同阶段比较LLM的表现。我们发现在每个训练阶段之后结果都有显著提高。我们可以用人工智能RLAIF代替RLHF中的人类,这在标注成本上有显著降低的同时有可能表现更好。
其他“AI原生”LLM AI模型公司(如Anthropic)使用这些强化学习(RL)技术的变化形式,而无需人类,他们称之为“宪法AI”。对于那些希望深入了解这种方法的人,这里是一篇评论。
阀门已经打开,利用人工智能强化学习对LLM AI模型进行微调、优化和改进。它们正在创造全新的Flywheel循环,从根本上改变了AI技术及其应用领域。它们是Amazon Flywheel的一种进化,但潜力可能更大。我们将来会详细介绍这个主题。
与此同时,我们需要将强化学习加入到我们的人工智能词汇中。在下次讨论人工智能的鸡尾酒聚会上试试看。
请继续关注。





