LLMs用于知识图谱构建和推理。
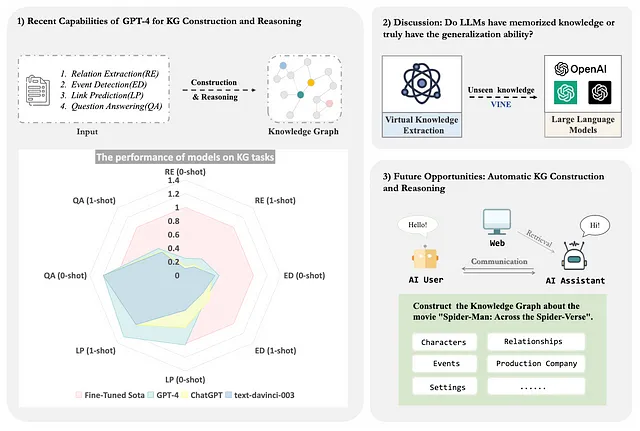
知识图谱
知识图谱是由实体、概念和关系组成的语义网络,可以催化各种场景下的应用,如推荐系统、搜索引擎和问答系统等。大型语言模型(LLMs),如 OpenAI 发布的 GPT-4,在大量数据上进行预训练,展示了极其强大的通用知识和问题解决能力[1] [2] [3] [4]。尽管有许多关于 LLMs 的研究,但对其在 KG 领域应用的系统探索仍然有限,因此像 GPT-4 这样的大型模型是否可以促进高效的 KG 构建和推理呢?
为了获得答案,我们调查了LLMs的潜在适用性,这些LLMs的示例包括ChatGPT和GPT-4。该博客的主要内容包括:
1. 对于不同类型的知识图谱,如事实、事件,以及不同领域,包括一般和垂直知识,对GPT-4的提取和推理能力进行分析。
2. GPT-4和ChatGPT在提取和推理能力方面的比较,以及对错误案例的分析。
3. 分析GPT-4提取未知知识的泛化能力。
4. 在大规模语言模型的时代,构建知识图谱推理的新方法前景。
论文链接: https://arxiv.org/abs/2305.13168
Github: https://github.com/zjunlp/AutoKG GitHub: https://github.com/zjunlp/AutoKG
KG建筑和推理的LLMs
因为我们无法访问GPT-4 API,所以我们利用ChatGPT-plus的交互界面,评估GPT-4在实体、关系和事件的零样本和单样本提取和推理能力。为了执行这些评估,我们随机抽取测试/验证集数据,并将结果与ChatGPT和一个完全受监督的基线模型进行比较。
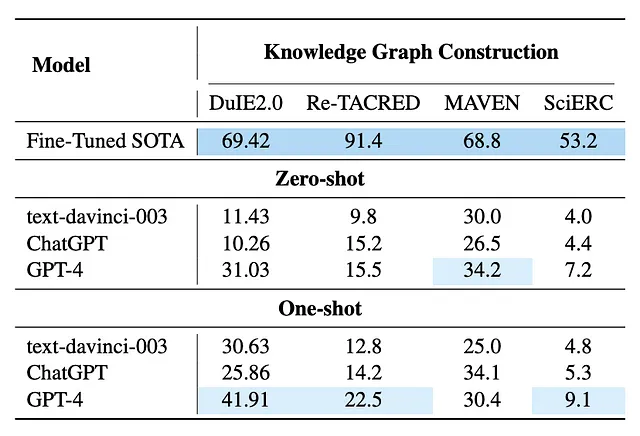
对于KG建设任务,我们选择DuIE2.0[5],RE-TACRED[6],MAVEN[7]和SciERC[8]作为实验数据集。由于某些数据集不提供实体类型,我们统一将其设置为仅提供所需的关系/事件类型的指令提示,而不明确指定要提取的实体类型。另外,对于KG推理和问答任务,我们在FB15K-237[9],ATOMIC 2020[10],FreebaseQA[11]和MetaQA[12]数据集上进行实验。
通过随机抽样数据进行测试,我们发现 GPT-4 在多个学术基准数据集中都以零样本和一样本方式获得了相对较好的性能。与 ChatGPT 相比,它显示出了改进。在提示中引入一个示例进一步提高了模型在零样本场景下的性能。这在一定程度上表明 GPT-4 具有从不同类型和领域中提取知识的能力。
然而,我们也观察到,目前GPT-4在知识图谱构建任务上的表现仍然不如完全监督的较小模型好。这一发现与先前相关工作[2][4]一致。更重要的是,在知识图谱推理任务中,所有大型模型都通过一次性训练或GPT-4通过零次训练达到或接近了最先进的性能。值得注意的是,这些结果基于随机抽样测试和交互界面评估(而不是API),这可能会受到测试集的数据分布和样本选择的影响。
此外,提示的设计和数据集本身的复杂性也对该实验的结果产生了显著影响。具体而言,我们发现 ChatGPT 和 GPT-4 在这 8 个数据集上的评估结果可能受以下因素的影响:
数据集:某些数据集中存在噪声和不清晰数据类型的问题(例如头实体和尾实体的实体类型缺失、复杂的上下文等)。
提示设计:语义不丰富的提示可能会影响提取性能(例如,整合相关的上下文学习[13]可以提高性能;Code4Struct [14]发现利用代码结构可以促进结构化信息提取)。值得注意的是,由于某些数据集缺乏实体类型,因此知识图谱构建任务中的提示说明不会指定实体类型,以确保在数据集上比较不同模型的能力时公平比较,这也可能在一定程度上影响实验结果。
评估方法:现有的评估方法可能不适用于评估像ChatGPT和GPT-4这样的大型模型的提取能力。例如,数据集中提供的标签可能无法完全覆盖正确答案,一些超出答案的结果仍可能是正确的(例如,由于同义词) 。
能力比较与错误案例研究
实体和关系提取
我们在SciERC、Re-TACRED和DuIE2.0上进行实验,每个数据集的测试/验证集中有20个样本,并使用标准的微型F1得分来评估结果。如表1所示,GPT-4在这些学术基准提取数据集中的零样本和一样本方式下表现相对较好。即使与ChatGPT相比,它也取得了一些进展,尽管它的性能尚未超过全监督小模型的性能。
学习
GPT-4 的零-shot 性能在所有三个调查数据集上展现了进步,在DuIE2.0中观察到最显著的改善。这里,GPT-4 的得分为31.03,而 ChatGPT 的得分为10.3。这个结果进一步证明了 GPT-4 在提取复杂和新知识方面的强大泛化能力。

如图1中的(1)和(2)所示,与ChatGPT相比,GPT-4在从头到尾的实体提取方面表现出更实质性的改进。具体来说,在Re-TACRED的示例句子中,目标三元组是(Helen Keller International,org:alternate_names,HKI)。然而,ChatGPT未能提取出这样的关系,可能是由于头尾实体间距离过近和谓词在此实例中的歧义性导致的。
相比之下,GPT-4成功提取了头实体和尾实体之间的“org:alternate_names”关系,完成了三元组的提取。这也在一定程度上展示了GPT-4相较于ChatGPT的语言理解(阅读)能力的提升。
一次性的
同时,文本指导的优化可以促进GPT-4的性能提升。
使用DuIE2.0数据集作为例子,考虑以下句子:“George Wilcombe于2008年被选入洪都拉斯国家队,并与该队参加了2009年北美和中美洲以及加勒比地区金杯赛。”相应的三元组应为(George Wilcombe,国籍,洪都拉斯)。
虽然这些信息没有在文本中明确说明,但是GPT-4成功提取了它们。这一结果不仅仅归因于单个训练实例提供了有价值的信息,还归因于GPT-4的综合知识库。在这种情况下,GPT-4根据他入选国家队推断了George Wilcombe的国籍。
事件提取
我们对MAVEN数据集中随机抽取的20个样本进行事件检测实验。与此同时,即使没有提供演示,GPT-4在事件提取任务上也取得了令人称赞的成果。在这里,我们使用F-score作为评估指标。
零射击
表格显示,GPT-4以零-shot的方式优于ChatGPT。此外,使用示例句“现在是阵容的成员,他同意更经常地唱歌。”,ChatGPT生成结果为“成为成员”,而GPT-4识别出三种事件类型:成为成员,同意或拒绝表演以及表演。
值得注意的是,在这个实验中,ChatGPT经常提供仅含单一事件类型的答案。相比之下,GPT-4更擅长获取上下文信息,能够产生更多样化的答案,并提取更全面的事件类型。
因此,GPT-4 在包含一个或多个关系的句子的 MAVEN 数据集上取得了优秀的结果。
一次性的。
在单次试验中,我们观察到在相同的设置下,ChatGPT的表现显著提高,而GPT-4的表现略有下降。单个演示的包含纠正了ChatGPT在零-shot环境下做出的错误判断,从而提高了其表现。在这种情况下,我们将集中分析GPT-4。

如图2所示,范例句子为“最终奖牌榜由印度尼西亚领先,其次是泰国和东道主菲律宾”。数据集中提供的事件类型为Process_end和Come_together。然而,GPT-4会生成三种结果:比较、收益和损失、以及排名。
在这个过程中,GPT-4 确实注意到句子中隐藏的排名和比较信息,但忽略了触发词“Final”对应于“Process_end”以及触发词“Host”对应于“Come_together”。
同时,我们的观察表明,在一次性设置下,当GPT-4无法正确识别类型时,它往往会产生更多的错误响应。这在一定程度上对GPT-4在样本上的表现有所影响。
我们假设这可能是因为数据集提供的类型不够明确。此外,在单个句子中存在多种事件类型进一步增加了这些任务的复杂性,导致次优结果。
链接预测
任务链接预测涉及两个不同数据集上的实验,即FB15k-237和ATOMIC2020。前者是一个随机抽样集,包含25个实例,而后者则包括23个实例,代表了所有可能的关系。
零样本
在表2中,GPT-4在零-shot链接预测任务中表现优于text-davinci-003和ChatGPT模型。值得注意的是,GPT-4在FB15k-237上的hits@1得分达到了最先进的水平,超过了微调模型的表现。
关于ATOMIC2020,虽然GPT-4仍然超过其他两个模型,但在蓝1分数方面,GPT-4的表现与达到最佳结果的精细调整SOTA之间存在相当大的差距。
经过对零样本情况下回答的仔细检查,可以看出ChatGPT在预测链接存在歧义的情况下,往往倾向于咨询更多的上下文信息以解决歧义,而不是直接给出答案。而GPT-4则更倾向于直接提供答案。这一观察结果表明两者在推理和决策过程中存在潜在差异。
一次性
文本指令的优化也被证明是增强GPT系列在链接预测任务中表现的有效方法。实证评估揭示出单次GPT-4在两个数据集上均可产生改进的结果,有助于准确预测三元组的尾实体。
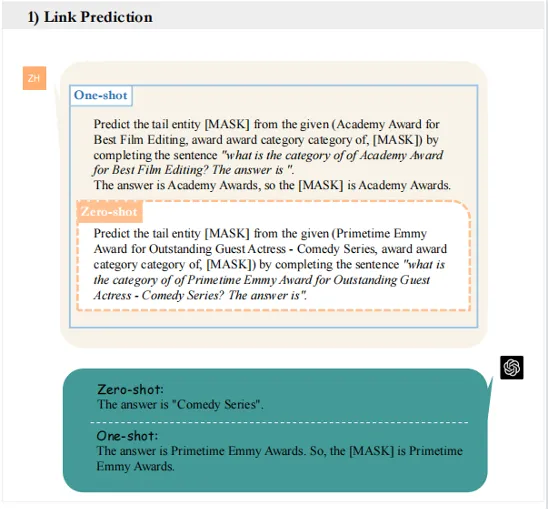
在图3的例子中(优秀客串女演员-喜剧类,奖项类别类别,[MASK]),目标[MASK]是艾美奖。在零样本设置下,GPT-4无法正确理解关系,导致将响应错误地定为喜剧系列。然而,当演示被融合时,GPT-4可以成功地识别出目标尾实体。
问答系统
我们在两个广泛使用的知识库问答数据集(FreebaseQA和MetaQA)上进行评估。我们从每个数据集中随机抽取20个实例。对于包含不同跳数问题的MetaQA,我们根据数据集中的比例进行抽样。我们用AnswerExactMatch作为两个数据集的评估指标。
零样本学习
如表2所示,Text-davinci-003、ChatGPT和GPT-4在FreebaseQA数据集上表现相同,它们都超过了先前完全监督的SOTA,并实现了16%的提高。然而,GPT-4在Text-davinci-003和ChatGPT方面并没有优势。至于MetaQA,大型语言模型和监督的SOTA之间仍存在较大差距。
这种差距的一个可能原因可能是问题有多个回答,而不是FreebaseQA数据集,那里问题通常只有一个答案。此外,MetaQA数据集提供的知识图无法被馈送到LLMs中,因为输入令牌长度有限制,而LLMs只能依靠其内部知识进行多跳推理,因此,LLMs经常无法覆盖所有正确的答案。

然而,GPT-4在回答更具挑战性的问题方面比text-davinci-003和ChatGPT分别表现出29.9点和11.1点的优越性,表明GPT-4在更具挑战性的问答任务中比text-davinci-003和ChatGPT更出色。
具体而言,MetaQA数据集中的图4中的示例问题是:“《老人聚集》作者编写的电影何时发行?”。回答这个问题需要进行多级推理过程,包括将电影与作者连接起来,并最终确定发行年份。值得注意的是,GPT-4能够正确回答这个问题,提供了1999年和1974年的发行日期。相比之下,ChatGPT和text-davinci-003未能提供正确的答案,凸显了GPT-4在多级问题回答任务中的卓越表现。
单发
我们还在单次设置下进行实验,通过随机从训练集中抽取一个例子作为场景内示范。表2中的结果表明,只有text-davinci-003从提示中受益,而ChatGPT和GPT-4都遇到了性能下降。这可以归因于臭名昭著的对齐税,在此种情况下模型为了与人类反馈对齐而牺牲了一部分场景内学习能力。
一般性分析:虚拟知识提取
根据以往的实验,显然大型模型能够迅速从最少的信息中提取结构化知识。这一观察结果引出一个问题,即关于大型语言模型性能优势的起源:是由于大量的文本数据在预训练阶段被利用,使得模型能够获得相关知识,还是由于其强大的推理和泛化能力?
为了深入探讨这个问题,我们设计了一个虚拟知识提取任务,旨在评估大型语言模型的推广和提取陌生知识的能力。
数据收集
识别当前数据集无法满足我们的需求的不足,我们推出了一份新颖的虚拟知识抽取数据集——VINE。具体而言,我们构建不存在于现实世界中的实体和关系,并将它们组织成知识三元组。随后,我们使用说明来让模型提取这种虚拟知识。这种抽取的有效性用于衡量大模型处理未见过的知识的能力。我们基于Re-TACRED数据集的测试集构建了VINE。构建过程的主要思想是用未见过的实体和关系取代原始数据集中的现有实体和关系。
由于像GPT-4这样的模型有大量的训练数据可用,很难找到它们不熟悉的单词。因此,我们利用了2022年1月和2023年2月由《纽约时报》主办的两项单词挑战竞赛的参与者的回答作为数据来源之一,旨在发现创意和易记的新单词来填补英语语言中明显的空白。此外,为了增加数据来源的多样性,我们通过随机生成字母序列来生成一部分新单词,创建长度在7到9个字符之间的随机序列(包括所有26个英文字母和符号“-”),并随机添加常见名词后缀。
初步结果
在我们的实验中,我们随机选取了十个句子,每个句子都包含不同的关系类型,供评估使用。在学习相同关系的两个示例后,我们评估ChatGPT和GPT-4在这十个测试样本上的表现。
我们的研究发现,在接受一定量的虚拟知识曝光后,ChatGPT在虚拟知识提取方面明显表现不及GPT-4。相比之下,GPT-4能够根据指令准确地提取未曾见过的实体和关系知识。值得注意的是,GPT-4成功提取了80%的虚拟三元组,而ChatGPT的准确度只有27%。

在图5所示的例子中,我们提供一个由虚拟关系类型和虚拟头部和尾部实体组成的三元组——[Schoolnogo、decidiaster、Reptance]和[Intranguish、decidiaster、Nugculous]——以及相应的演示。结果表明,GPT-4有效地完成了虚拟三元组的提取。
因此,我们暂时得出结论,GPT-4表现出相对较强的泛化能力,能够通过指示快速获取提取新知识的能力,而不仅仅依靠相关知识的记忆(相关工作[17]已经实证发现大型模型具有非常强的指示泛化能力)。
未来的机遇:LLM的多智能体自动化知识图谱构建和推理。
最近,LLMs(语言模型)引起了相当多的关注,并且在各种复杂任务中表现出专业水平。尽管如此,像ChatGPT这样的技术的成功仍然主要取决于大量的人力投入来引导生成对话文本。从模型开发的角度来看,这个过程仍然需要耗费大量的人力和时间。因此,研究人员开始探索启用大型模型自主生成引导文本的潜力。
例如,AutoGPT[18] 可以独立生成提示并执行任务,例如事件分析、市场计划创建、编程和数学运算。同时,CAMEL[19] 探索了沟通代理之间自主合作的潜力,并引入了一种新的合作代理框架,称为角色扮演。该框架使用启示性线索确保与人类意图的一致性。在此研究基础上,我们进一步探究:是否可利用沟通代理完成知识图谱构建和推理任务?

在这个实验中,我们在CAMEL中使用了角色扮演方法。
如图所示,人工智能助手被指定为顾问,而人工智能用户则为知识图谱领域专家。在接收到提示和指定角色分配后,任务特定代理会提供详细的描述以具体化概念。
接下来,AI 助手和 AI 用户在多方设置中合作完成指定任务,直到 AI 用户确认完成。实验样例表明,使用多代理方法可以更有效、全面地构建与电影《绿皮书》相关的知识图谱。这个结果也强调了基于LLM的代理在构建和完成知识图谱方面的优越性。
结论和未来工作
在本文中,我们旨在初步探究GPT系列等LLM在诸如KG构建和推理等任务上的表现。
尽管这些模型在这些任务上表现出色,我们提出了一个问题:LLM在提取任务中的优势是来自它们庞大的知识库,还是它们强大的上下文学习能力?为了探讨这个问题,我们设计了一个虚拟知识提取任务,并创建了相应的数据集进行实验。结果表明,大模型确实具有强大的上下文学习能力。
此外,我们提出了一种创新的方法,通过采用多个代理来完成知识图谱的构建和推理任务。这种策略不仅减轻了人工劳动力,而且弥补了各个领域人类专业知识的不足,从而提高了LLMs的性能。
虽然我们的研究得出了一些结果,但它也具有某些局限性。
1. 如前所述,由于无法访问GPT-4 API,我们必须依赖交互式界面来进行实验,不可避免地增加了工作量和时间成本。
2. 此外,由于 GPT-4 的多模态功能目前尚未对公众开放,我们暂时无法深入探讨其在多模态处理方面的表现和贡献。
我们期待着未来的研究机会,以进一步探索这些领域。
参考资料
[1] 语言模型提示的推理:一项调查 2022
[2] 通过与ChatGPT 2023聊天实现零样本信息提取
[3] 大型语言模型并不是一个好的少样本信息提取器,但它是一个好的难例重新排序器!2023年
[4] 探索使用ChatGPT进行事件提取的可行性 2023
[5] DUie: 一个用于信息提取的大规模中文数据集 NLPCC2019
[6] 重新整理Tacred:解决Tacred数据集的缺陷AAAI2021
[7] MAVEN:一个庞大的通用领域事件检测数据集 EMNLP2020
[8] 科学知识图谱构建的实体、关系和指代多任务识别 EMNLP2018
[9] 代表文本用于文本和知识库联合嵌入 EMNLP2015
[10] (彗星-) 原子 2020 年:关于符号和神经常识知识图谱的AAAI2021
[11] FreebaseQA:一个新的事实型 QA 数据集,与 Freebase 匹配的闲聊式问题-答案对。NAACL-HLT2019。
[12] AAAI2018知识图谱问答的变量推理
[13]2012年情境学习调查
[14] Code4Struct:自然语言中的少样本结构化预测代码生成 2022
[15] https://www.nytimes.com/2022/01/31/learning/february-vocabulary-challenge-invent-a-word.html [15] https://cn.nytimes.com/education/20220201/february-vocabulary-challenge-invent-a-word/zh-hans/
[16] https://cn.nytimes.com/education/20230202/student-vocabulary-challenge-invent-a-word/zh-hans/
[17] 更大的语言模型以不同的方式进行上下文学习
[18] https://github.com/Significant-Gravitas/Auto-GPT [18] https://github.com/Significant-Gravitas/Auto-GPT
[19] 骆驼:大规模语言模型社会的“心智”探索交流代理人 2023
[20] https://github.com/zjunlp/EasyInstruct 保持HTML结构,将以下英文文本翻译为简体中文: [20] https://github.com/zjunlp/EasyInstruct







