使用LLMs创建GitHub文档机器人
我的开源仓库中的所有文档都是由GPT4生成的,我可以通过单击按钮更新这些文档。

自动化是由AgentHub提供动力,它能够读取我的GitHub项目、生成新的Markdown文档并为我发布PR。以下是我如何制作它以及你如何构建自己的方式。
(链接到由该流程生成的文档)
为什么?
试图让文档保持最新状态就像在潮汐线以下建造沙堡。你可以尽你所能完善它,但贡献的浪潮最终会席卷而来,将其变成毫无意义的泥沙。这在拥有活跃社区的开源项目中尤为真实。

这种艺术的本质不在于其长寿,而在于它短暂的存在,提醒我们真正的美丽常常存在于不稳定的事物,就像日落一样。 - ChatGPT
让我们在这个比方中忽略瞬时艺术的美丽,并认识到重新编写文档是一种痛苦。它可以是如此令人沮丧,以至于许多项目忽略了它,让它们的文档降级到需要完全重写的程度。即使他们为此分配了时间,一个知道足够多知识去写文档的工程师也不应该花费宝贵的时间来编写它们。
我在AgentHub上建立了一个由LLM驱动的流水线,为我自己的开源仓库生成文档。我的沙堡自我重建。
它是如何运作的
每当管道运行时,它会吸收我GitHub 存储库中的所有文件,通过 LLM 将它们传递,并要求其生成描述性的 markdown 文档,最后使用我的 GitHub 凭据提出 PR。
为了背景,我正在记录的开源项目是AgentHub操作员存储库。它包括作为AgentHub管道构建块的模块组件(操作员)。每个运算符都是它自己的短Python文件,旨在完成特定任务(例如:HackerNews抓取HN帖子,IngestPDF通过并将内容输出为纯文本读取pdf)。
这个解决方案是使用运算符构建的,并且同时记录了这些运算符。希望这不会太令人困惑。
以下是我在AgentHub上的管道:
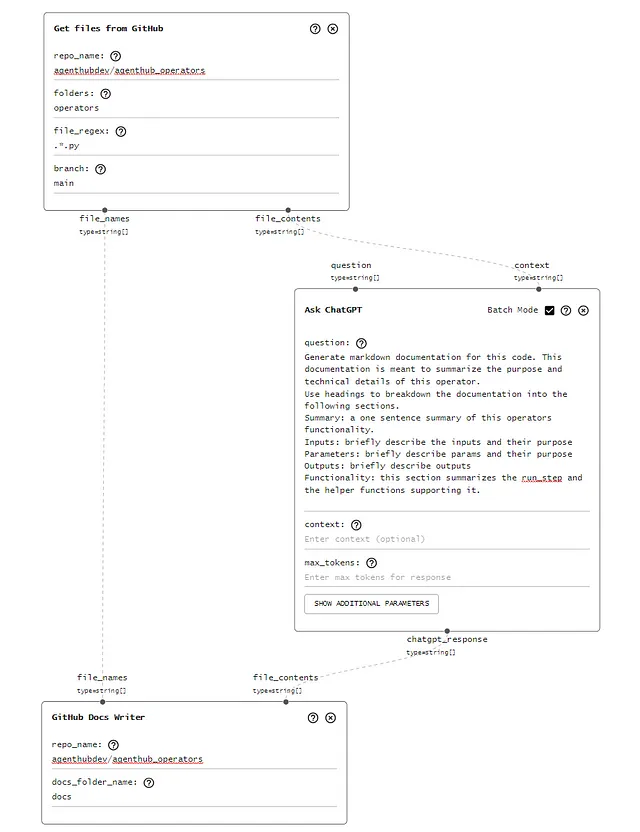
阅读 GitHub 文件:
首先,我需要从GitHub抓取文件的内容。我使用“从GitHub读取文件”操作。它返回带有纯文本文件内容的文件名称。
def read_github_files(self, params, ai_context):
repo_name = params['repo_name']
folders = params.get('folders').replace(" ", "").split(',')
file_regex = params.get('file_regex')
branch = params.get('branch', 'master')
g = Github(ai_context.get_secret('github_access_token'))
repo = g.get_repo(repo_name)
file_names = []
file_contents = []
def file_matches_regex(file_path, file_regex):
if not file_regex:
return True
return re.fullmatch(file_regex, file_path)
def bfs_fetch_files(folder_path):
queue = [folder_path]
while queue:
current_folder = queue.pop(0)
contents = repo.get_contents(current_folder, ref=branch)
for item in contents:
if item.type == "file" and file_matches_regex(item.path, file_regex):
file_content = item.decoded_content.decode('utf-8')
file_names.append(item.path)
file_contents.append(file_content)
elif item.type == "dir":
queue.append(item.path)
for folder_path in folders:
bfs_fetch_files(folder_path)
ai_context.add_to_log(f"{self.declare_name()} Fetched {len(file_names)} files from GitHub repo {repo_name}:\n\r{file_names}", color='blue', save=True)
ai_context.set_output('file_names', file_names, self)
ai_context.set_output('file_contents', file_contents, self)
return True(源代码)
问ChatGPT:
这是工作流程的中流砥柱。我将上一步骤的每个文件内容传递为该“Ask ChatGPT”操作符的输入/上下文。我使用以下非常明确的提示来生成 markdown 文档。
为此代码生成 Markdown 文档。该文档旨在总结此运算符的目的和技术细节。
使用标题将文档分成以下几个部分。
摘要:简述该运算符功能的一个句子。
输入: 简要描述输入及其用途。
参数:简要描述参数及其目的。
产出:简要描述产出
功能:此部分总结了 run_step 和支持它的辅助函数。
def run_step(self, step, ai_context):
p = step['parameters']
question = p.get('question') or ai_context.get_input('question', self)
# We want to take context both from parameter and input.
input_context = ai_context.get_input('context', self)
parameter_context = p.get('context')
context = ''
if input_context:
context += f'[{input_context}]'
if parameter_context:
context += f'[{parameter_context}]'
if context:
question = f'Given the context: {context}, answer the question or complete the following task: {question}'
ai_response = ai_context.run_chat_completion(prompt=question)
ai_context.set_output('chatgpt_response', ai_response, self)
ai_context.add_to_log(f'Response from ChatGPT: {ai_response}', save=True)(源代码)
创建拉取请求:
最后,如果我必须复制输出并自己提PR,这个自动化将成为一项繁琐的任务。这最后一步会将文件名列表和文件内容(markdown文档)创建为一个由我的账户提出的PR。
这是一个公关案例示例。
def run_step(
self,
step,
ai_context : AiContext
):
params = step['parameters']
file_names = ai_context.get_input('file_names', self)
file_contents = ai_context.get_input('file_contents', self)
g = Github(ai_context.get_secret('github_access_token'))
repo = g.get_repo(params['repo_name'])
forked_repo = repo.create_fork()
base_branch_name = 'main'
base_branch = repo.get_branch(base_branch_name)
all_files = []
contents = repo.get_contents("")
while contents:
file_content = contents.pop(0)
if file_content.type == "dir":
contents.extend(repo.get_contents(file_content.path))
else:
file = file_content
all_files.append(str(file).replace('ContentFile(path="','').replace('")',''))
new_branch_name = f"agent_hub_{ai_context.get_run_id()}"
GitHubDocsWriter.create_branch_with_backoff(forked_repo, new_branch_name, base_branch.commit.sha)
run_url = f'https://agenthub.dev/agent?run_id={ai_context.get_run_id()}'
for file_name, file_content_string in zip(file_names, file_contents):
file_path = file_name
name = os.path.splitext(os.path.basename(file_path))[0] + '.md'
docs_file_name = params['docs_folder_name'] + '/' + name
commit_message = f"{file_path} - commit created by {run_url}"
if docs_file_name in all_files:
file = repo.get_contents(docs_file_name, ref=base_branch_name)
forked_repo.update_file(docs_file_name, commit_message, file_content_string.encode("utf-8"), file.sha, branch=new_branch_name)
else:
forked_repo.create_file(docs_file_name, commit_message, file_content_string.encode("utf-8"), branch=new_branch_name)
# Create a pull request to merge the new branch in the forked repository into the original branch
pr_title = f"PR created by {run_url}"
pr_body = f"PR created by {run_url}"
pr = repo.create_pull(
title=pr_title,
body=pr_body,
base=base_branch_name,
head=f"{forked_repo.owner.login}:{new_branch_name}"
)
ai_context.add_to_log(f"Pull request created: {pr.html_url}")
@staticmethod
def create_branch_with_backoff(forked_repo, new_branch_name, base_branch_sha, max_retries=3, initial_delay=5):
delay = initial_delay
retries = 0
while retries < max_retries:
try:
forked_repo.create_git_ref(ref=f"refs/heads/{new_branch_name}", sha=base_branch_sha)
return
except Exception as e:
if retries == max_retries - 1:
raise e
sleep_time = delay * (2 ** retries) + random.uniform(0, 0.1 * delay)
print(f"Error creating branch. Retrying in {sleep_time:.2f} seconds. Error: {e}")
time.sleep(sleep_time)
retries += 1(源代码)
GPT 3.5与GPT 4对比
AgentHub让您选择要运行哪个模型来运行管道。我尝试了GPT-3.5-turbo和GPT4这两种模型来完成此任务。 GPT4文档不会让读者想入非非,更接近我写作的风格。
以下是每个模型对同一相对复杂的运算符进行文档化的示例。