理解基于向量检索的限制以建造LLM强化的聊天机器人—(1/3部分)
本博客是一系列帖子中的第一篇,旨在解释为什么部署具有大型语言模型(LLMs)的领域专业聊天机器人的主流管道过于昂贵和低效。在本文中,我们讨论向量数据库为什么在实际生产流水线中部署时存在根本性限制,尽管最近流行程度急剧上升。在接下来的帖子中,我们将阐述ThirdAI最新产品如何解决这些缺点,并以低成本实现在生产环境中部署LLM-powered检索的愿景。
动机
具有特定领域技能的聊天机器人是ChatGPT最受欢迎的企业应用程序。具有指定知识库的自动问答功能可以使任何雇主的员工更加高效,同时节省员工宝贵的时间。例如,如果员工与客户互动,将所有与该客户的历史互动随手可得会非常方便。如果您想为大型代码库做出贡献,如果您可以快速获得任何现有功能的细粒度级别,那么您就可以变得非常高效。列表还在继续。
ChatGPT是一款很好的对话工具,它通过互联网上的大量文本信息进行训练。如果您向ChatGPT询问互联网上的常识问题,它可以相当好地回答。然而,它也有一些显著的局限性。ChatGPT无法回答其所训练数据之外的问题。因此,如果您问ChatGPT:“谁赢得了2022年世界杯足球比赛?”它就无法回答,因为它没有接受过任何2021年9月之后的信息训练。企业拥有非常专业、专有且不断更新的信息库,而ChatGPT开箱即用并不能成为这些知识库的查询助手。更糟糕的是,现在已经众所周知,没有正确的防护措施向ChatGPT提出查询很可能导致虚构的答案。
幸运的是,目前有相当大的活动在利用提示来解决上述两个缺点。
什么是Prompting?
提示是一个用来告诉对话代理所需的所有特定信息以回答问题的新术语。它依赖于代理的对话能力来产生一个精练的回答。如果您希望ChatGPT回答一个不属于其训练集的特定问题,则必须使ChatGPT意识到它需要知道的所有信息不超过4096个标记(或大约3200个单词;对于GPT-4,限制为25000个单词),然后使用给定的“上下文”问它同样的问题。
然而,無論聽起來多傻,提示仍然是一種有價值的能力。通過生成式人工智能的顯著進步,自動化人類對話成為了我們最近實現的罕見功績。有效地建立一個查詢助手歸結為“檢索相關資訊”,然後使用ChatGPT的能力,基於檢索到的信息生成對話回答。我們可以看到,這自動地將警戒線圈定在幻覺周圍,因為對話代理人被迫將答案基於檢索到的文本進行研究,該文本是知識庫的子集。
最难的部分总是在大海捞针!
嵌入和向量数据库生态系统:在任何给定语料库上使用ChatGPT构建扎实的查询助手。
有许多聊天机器人应用程序是使用Langchain构建的,您可以将任何文本语料库引入其中,然后使用ChatGPT进行交互。所有这些应用程序都是基于标准嵌入式信息检索过程构建的。
该过程有两个主要阶段。第一阶段是预处理步骤,生成嵌入并建立向量索引以进行近邻查询。索引建立后,下一个阶段是查询。我们简要介绍这两个阶段。
预处理步骤: 该步骤将所有原始文本进行处理,并建立一个可以高效搜索的索引。该过程在下图中描述。
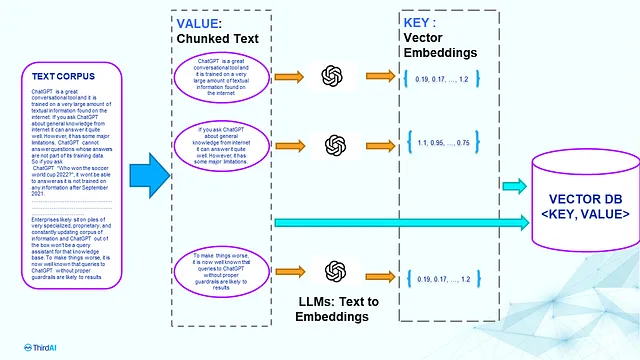
让我们假设我们有一个文本文档语料库需要为问答做准备。第一步是将语料库(或文本文档)分成小的文本块,我们将其称为块(该过程也称为块分析)。然后将每个块馈送到像BERT或GPT这样的训练过的语言模型中,以生成向量表示,也称为嵌入。然后将文本嵌入对存储在向量数据库或
- 注意:对LLM进行任何更改或更新都需要重新索引向量数据库中的所有内容。您需要完全相同的LLM进行查询。不允许更改维度。
- 隐私风险:所有文本必须传输到嵌入模型和向量数据库。如果两种服务的管理方式不同,您将在两个不同的位置创建完整数据的两个副本。
- 成本意识:完整文本语料库中的每个令牌都会传输到 LLM 和向量数据库。未来,若您通过微调、升级模型,甚至是增加维度来更新您的 LLM,则需要重新索引并再次支付全部费用。
- 托管服务成本估算:让我们以建立一个基于所有医学文摘知识库的聊天机器人来构建一个医疗问答应用程序的谦虚估计为例。Pubmed大约有3500万份摘要,大约需要100M个嵌入来涵盖这些摘要。假设每个块有250个标记,那么我们将有约250亿个标记。即使我们使用Pinecone的谦虚向量数据库计划(Performance)和OpenAI的价格更便宜的嵌入模型(Babbage V1),我们也需要支付大约7000至8000美元的向量数据库费用,不包括任何存储费用。此成本不包括任何储存费用。此外,基于标记数量每次更改嵌入模型时,需要支付125,000美元的一次性嵌入生成成本。如果我们每月进行100M次查询,则需要支付每月额外至少$250,000的查询嵌入服务和OpenAI的响应生成的费用。值得注意的是,PubMed是较小的公共检索数据集之一。企业很可能拥有10-100倍的更大语料库。
2. 查询阶段:嵌入和近似最近邻搜索,然后通过提示进行生成。
该步骤会获取用户键入的问题,从向量数据库中搜索与问题“最相关”的文本内容,然后基于该信息向GenAI征询回答。以下是这些步骤的概述,如图所示。
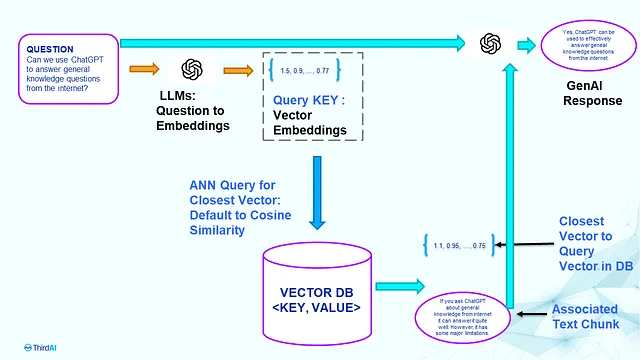
对于问答阶段,流程是简单明了的。我们首先使用用于索引向量数据库的相同 LLM 生成查询的向量嵌入。这个嵌入作为查询 KEY,并执行近似最近邻搜索 (ANN) 来查找与查询嵌入最接近的一些向量。接近度的度量是预定义的,固定的,通常是余弦相似度。在识别出接近向量之后,它们对应的文本块就成为与问题相关的信息。然后将相关信息和问题通过提示提供给生成式 AI,如 ChatGPT,以生成响应。
- 注意:查询延迟是三个延迟时间之和:问题文本嵌入延迟 + 矢量数据库检索延迟 + GenAI 的文本响应生成延迟。如果您使用多个托管服务和不同的微服务,请准备至少等待数百毫秒才能获得答案。显然,对于搜索引擎、电子商务和其他延迟关键的应用程序,超过 100 毫秒的延迟会导致较差的用户体验,这是不可接受的。这是亚马逊博客的链接,详细介绍了每延迟 100 毫秒会导致 1% 销售额下降的情况。
- 成本:如前一节所讨论的,查询的成本可能相当大,并且一旦将您的数据放在外部托管服务平台上,这些成本就会被锁定。
嵌入式和向量搜索的已知基本限制:为什么现代信息检索智慧主张学习索引?
除了上面提到的延迟、成本、无法灵活地更新模型和隐私问题之外,将嵌入过程(KEY生成)与基于余弦相似度的ANN(文本检索)分离的根本缺陷也存在。
一个牵强的假设和Andrej Kaparthy最近的实验:整个生态系统背后的暗示是向量嵌入之间的余弦相似性将检索到相关文本。众所周知,可能会有更好的选项。这些LLM未调整好余弦相似度检索,并且其他相似度函数可能效果更好。以下是Andrej Kaparthy的帖子以及他如何发现基于SVM的相似性更好的笔记本。
深度学习革命告诉我们,联合优化的检索系统总是比嵌入然后ANN的断开过程更好,其中ANN过程完全忽略嵌入部分,反之亦然。
因此,如果向量搜索生态系统的最终目标是为所提出的问题检索“相关文本”,为什么要使用两个不连贯的过程呢?为什么不建立一个统一的学习系统,给定一个问题文本,返回“最相关”的文本呢?难怪安德烈发现学习的SVM比简单点积检索更好。信息检索社区已经为几乎半个世纪建立了这样的联合优化嵌入和检索系统。
神经信息检索系统中最有效的形式是学习索引。在本博客的第二部分/第三部分中,我们将回顾学习索引,并讨论以前在行业中部署的学习系统。我们将回顾一种端到端学习索引系统的理念,完全绕过了基于向量的昂贵且繁琐的高维近邻搜索。
在最后一部分(第3/3部分),我们将讨论ThirdAI的稳定版学习索引API以及其与Langchain和ChatGPT的集成。我们的解决方案避开了向量数据库检索的昂贵、缓慢和僵化限制,我们迫不及待地想分享我们所构建的内容!