LLM提示的入门指南
如何设计您的自然语言提示,以从大型语言模型中获得最佳答案

大型语言模型(LLMs)使得每个人都可以通过自然语言提示而不是代码与AI进行交互。语言现在作为复杂模型的接口,这使得有必要更仔细地研究我们使用的提示。
当使用正确时,生成模型可以为企业产生非常有价值的结果。因此,正确设定提示是利用LLMs巨大潜力的必要条件,特别是当您要将其纳入产品中时。这就是为什么整个行业围绕“提示工程”主题形成的原因。在本文中,我们将解释这种技术的方法,并分享提示的dos和don'ts。
什么是提示?
提示是给LMM的指令。如果您已经与ChatGPT等LMM进行了交互,您就已经使用了提示。理想情况下,提示应该引出一个正确、形式和内容充分、长度合适的答案。
本质上,提示就是将你的意图打包成一个自然语言查询,使模型返回所需的响应。
如何提供好的提示
好的提示遵循两个基本原则:清晰和具体。清晰描述使用简单明了、避免术语和过于复杂的词汇。所以,与其让您的查询简短有力,不如采取冗长的方式,使您的要点足够清晰地传达给LLM。
不清晰提示的示例:
Who won the election?一个明确的提示示例:
Which party won the 2023 general election in Paraguay?特异性则指需要上下文衬托。告诉你的模型需要了解的所以信息来回答你的问题。有时,这几乎可以涉及到讲故事的领域。
一个不具体的提示示例:
Generate a list of titles for my autobiography.一个具体提示的例子:
Generate a list of ten titles for my autobiography. The book is about my journey as an adventurer who has lived an unconventional life, meeting many different personalities and finally finding peace in gardening.让我们来看看一些技巧,让我们的提示更好。
快速工程技巧
提示不是一门科学,称其为“工程”可能有点牵强。但LLM的研究者和用户已经确定了一些技巧,可以持续提高模型的响应能力。
说“要做”,不要说“不要做”。
这个观点实际上延续了我们关于特定性的主题,因为“做”指示本质上比“不要”更具体。因此,与其告诉模型不要做什么,通常最好明确地指定我们希望它做什么——如果我们知道这是什么。
让我们想象,在之前的例子中,我们想要确保LLM不会生成过长的标题(因为这些模型倾向于这样做)。与其说:
Don't make the titles too long最好具体明确:
Each title should be between two and five words long.### 使用少量样本提示
在我们的示例中,我们要求一项特定的项目(自传标题),长度为两到五个单词。这种没有任何具体示例的指令被称为“零射提示”。
大多数模型都受益于“少量示范提示”,即向模型提供一些示例以学习所需的模式。在我们的提示中,我们可以添加一些现有的标题作为示例,帮助模型有所感触,从而找到我们所追求的。
Here are some examples: Long walk to freedom, Wishful drinking, I know why the caged bird sings.有意义地构建你的提示语。
像引号、项目符号、换行等元素可以让人更容易解析文本。你知道吗?对于LLMs同样适用。让我们将这个见解应用到之前的例子中,并再次拼写出完整的提示。
Generate a list of ten titles for my autobiography. The book is about my journey as an adventurer who has lived an unconventional life, meeting many different personalities and finally finding peace in gardening. Each title should be between two and five words long.
### Examples of great titles ###
- “Long walk to freedom”
- “Wishful drinking”
- “I know why the caged bird sings”现在我们已经完善了提示,LLM的输出是什么样子?以下是ChatGPT的回答:
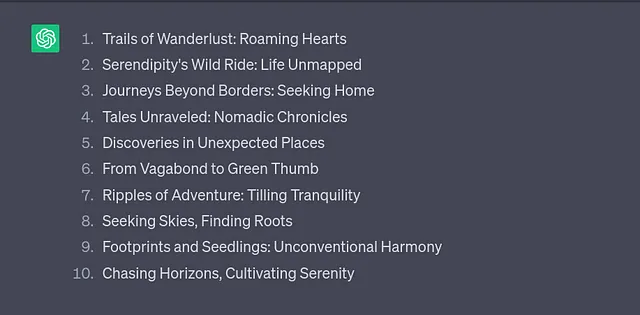
"寻找天空,发现根源"太有趣了,我绝对会考虑读这本书。
使用引导词
有时候,最简单的技巧是最有效的。东京大学的研究人员表明,在模型给出响应之前,告诉它“一步一步地思考”可以生成更准确的结果并帮助模型纠正自己的错误。这种方法被称为“引导用语”,因为我们轻柔地引导模型朝着更有效的问题解决计划方向发展。
该模型被迫将解决方案拆分为多个更易管理的步骤,而不允许仅凭猜测。看到这种简单技巧如何改善模型的表现令人惊叹。这里有一个需要一点递归思考的数学难题的例子:
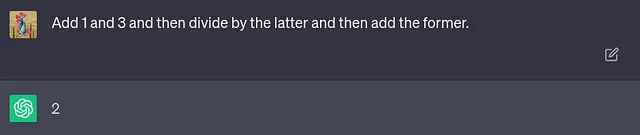
LLM自信地回答了——并且错了。当我们要求它“逐步思考”时,会发生什么呢:
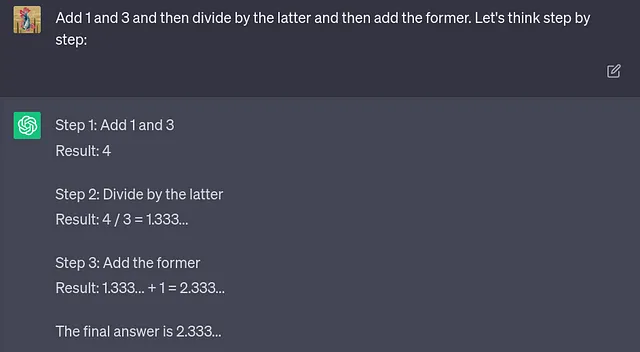
而这一次,最终答案是正确的。
引发陷阱
除了这些改进技术外,了解哪些指令元素可能会使模型偏离轨迹也是有帮助的。例如,一些人尝试在他们的提示中加入要求短而简洁的单词回答,以防止模型冗长。
然而,正如最后一个例子所显示的那样,当涉及到LLMs时,冗长的答案可能并不是坏事,而是这些模型用来找到正确答案的一种技术。LLMs可能很快就会学会保留他们的思维过程。与此同时,我们应该让他们自由发挥,避免请求一字一句的答案。
另一个问题是当你超过了模型的上下文长度时会发生。由于这些大型Transformer模型的性质,LLM的“上下文窗口”(它可以一次处理的文本部分)包括提示和其响应。如果您超过了模型的上下文长度,它的输出将会降低。
虽然这是一个迷人的话题,但也是一个相当复杂的话题——模型之间的上下文长度差异很大,而且测量提示长度甚至都不是微不足道的。只要记住,如果提示长度成为问题,您应该考虑把问题分解成较小的步骤。
成为更优秀的提示者
本文主要参考 Vladimir Blagojevic 的网络研讨会「使用 Haystack 提示 LLMs」。在此研讨会中,深入的成员 Vladimir 深度探究了提示技术,并展示了我们的开源自然语言处理框架 Haystack 如何提供正确的工具来切实达到优秀的提示效果。
为了获得更多关于如何提出出色提示的技巧,请查看我们的提示设计指南。
提示语在Agents中也扮演着巨大的角色:这是一种最新的有趣趋势,让你掌握LLMs的力量。Agents接收到一种“超级提示语”,指示LLM将其推理分解成可管理的步骤,并将其委托给认为最有能力解决任务的工具。请查看我们关于Agents的博客文章以了解更多信息。
最后,你并不总是需要自己编写提示语。请前往我们的提示中心,您可以找到各种应用程序的提示,您可以直接使用或根据自己的喜好进行调整,以获得最佳的LLM答案。