释放潜力:利用ChatGPT进行增强机器翻译

机器翻译得到了ChatGPT的强大语言模型的整合的革命性变革。为了优化ChatGPT在这项任务上的表现,采用了两个关键技术:温度调整和任务特定和领域特定提示的整合。
- 温度:温度参数在塑造ChatGPT的性能方面起着至关重要的作用。通过调整温度,我们可以控制生成响应的语言多样性。较高的温度会导致更多样化和创造性的输出,而较低的温度则会产生更确定性和语法正确的文本。然而,在具有高度确定性的任务(例如机器翻译)中,多样化的生成可能会妨碍翻译质量。在这种情况下,设置较低的温度可以通过确保更精确和可靠的翻译来提高性能。
- 任务特定提示(TSP):ChatGPT主要是一个会话系统,由于任务不一致,可能在翻译任务方面存在局限性。为了解决这个问题,提出了任务特定提示(TSP),以强调任务信息并弥合会话和翻译之间的差距。通过整合任务特定提示,ChatGPT可以更好地理解并使其响应与期望的翻译目标相一致。TSP可以显著提高ChatGPT的性能,尤其是在任务特定指导至关重要的复杂任务中。
- 领域特定提示(DSP):与传统机器翻译系统不同,ChatGPT具有将额外信息(例如人类交互)通过输入提示合并的优势。这种灵活的交互方式使ChatGPT能够减轻经典机器翻译方面的挑战,包括跨领域通用性。引入领域特定提示(DSP)来提供领域导航信息,增强ChatGPT在不同领域中的普适性。始终提供正确的领域信息可以持续提高ChatGPT的性能。然而,提供错误的领域信息可能会导致性能显著降低,凸显出准确和相关的领域特定提示对于实现最佳结果的重要性。
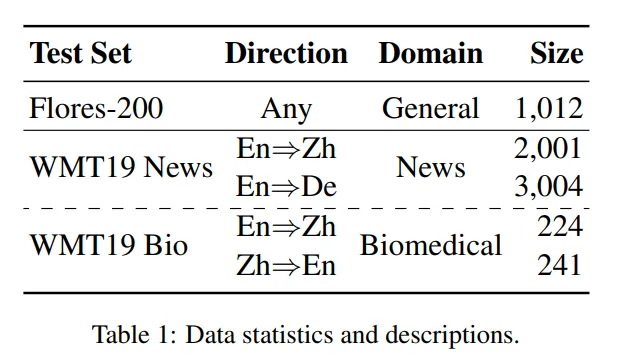
下面评估中使用的数据集:
1. 温度:
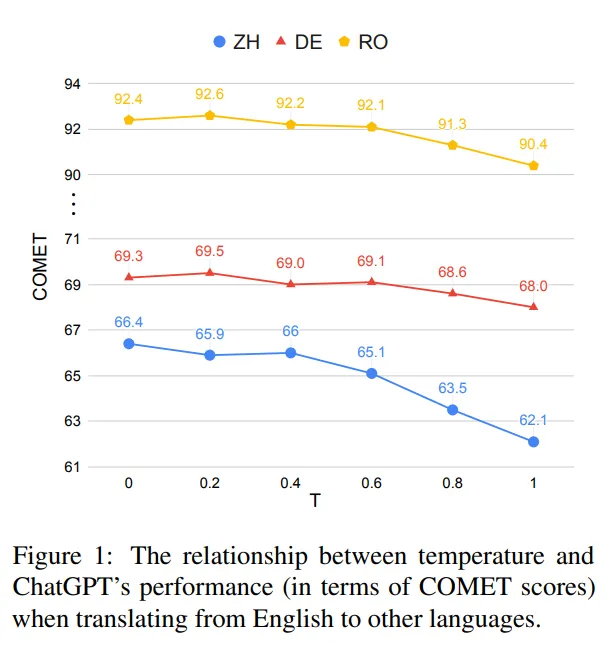
温度设置在ChatGPT的机器翻译任务表现中发挥着至关重要的作用。为了探究其影响,我们进行了实验,比较了不同温度值(从0到1)下ChatGPT的表现。评估是针对三个翻译方向进行的:英语⇒罗马尼亚语、英语⇒中文和英语⇒德语。
结果如图1和2所示,表明ChatGPT的性能受温度设置的影响较大。随着温度的升高,COMET和BLEU得分都会明显降低。值得注意的是,ChatGPT对温度的敏感程度因语言对而异。例如,在翻译德语等高资源语言时,温度的影响相对较小。然而,对于像中文这样的复杂语言,从0到1的温度变化会导致性能显著降低(对于中文,COMET值下降4.3分,BLEU值下降3.7分)。
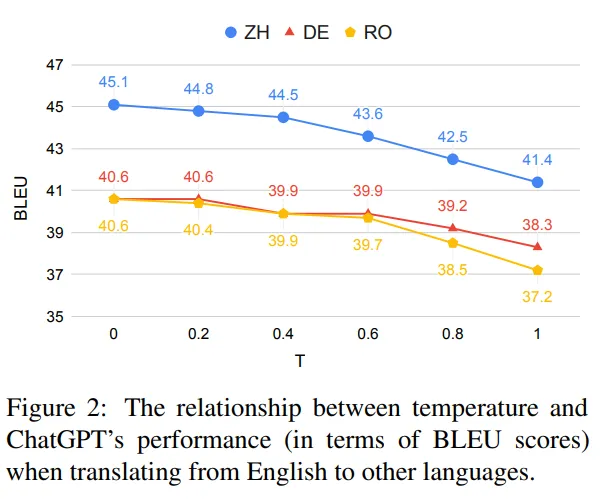
可能导致不同语言对温度的影响不同的一个可能解释是训练数据可用性的差异。资源可用性的相当大的差异影响语言模型的信心水平,从而影响其表现。鉴于这些观察结果,在随后的实验中采用0度作为默认设置。这个选择旨在最大化ChatGPT的潜力,并确保翻译的稳定生成。
总体而言,温度设置对ChatGPT在机器翻译任务中的性能有很大影响。必须找到最佳平衡,以实现准确可靠的翻译,同时允许足够的语言多样性和流利度。
2. 任务特定提示
为了解决任务间隙并提高ChatGPT作为普适机器翻译引擎的表现,我们引入了任务特定提示(TSP)。TSP旨在通过在先前工作(Jiao等人,2023年)的最佳翻译模板前加上句子“您是机器翻译系统。”来强调翻译任务信息。用于多语言翻译的提示列于表2中,其中[TGT]代表目标语言。

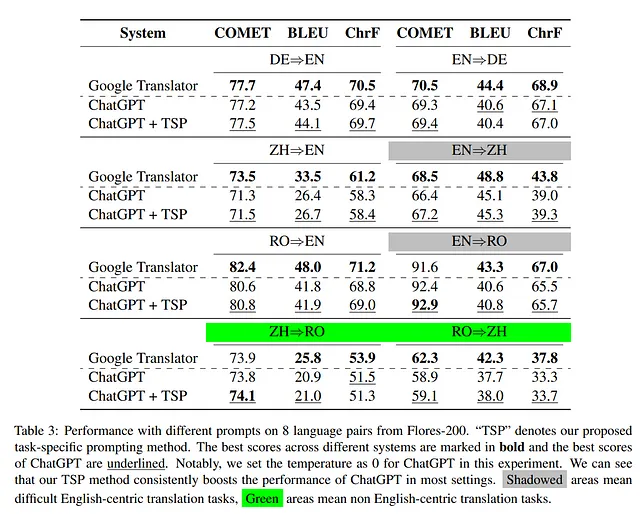
在四种语言对上,比较了不同模型的性能,涵盖了八个独特的翻译方向。这些语言对包括德语⇔英语(高资源)、罗马尼亚语⇔英语(低资源)、中文⇔英语(远程语言)和中文⇔罗马尼亚语(非英语为中心)。结果在表3中呈现,并突出了以英语为中心和非英语为中心的语言方向。
2.1 以英语为中心的语言配对:
ChatGPT在以英语为中心的翻译语言对中的表现进行评估。对德语⇔英语、罗马尼亚语⇔英语和中文⇔英语进行实验。
结果:TSP方法在一些语言对中(如英语⇒罗马尼亚语)的翻译表现比Google Translator更加优秀,而在一些语言对中的表现则相当。TSP方法能够持续改善原始ChatGPT的表现特别是在翻译到资源匮乏的或者远古语言时。值得注意的是,当翻译至英语时,TSP方法可以提升+0.2的平均COMET分值;而在英语⇒中文和英语⇒罗马尼亚语语言对中,分别提升+0.8和+0.5的COMET分数。有人猜测,高资源训练数据能够帮助模型更好地理解具体任务,从而减少额外的任务相关信息需求。然而,就字词类指标而言(BLEU 和 ChrF),TSP方法并不能稳健地填补任务空缺。
2.2 非以英语为中心的语言对:
ChatGPT在非以英语为中心的语言对中的表现也得到了评估。观察到在处理非以英语为中心的MT语言对时,ChatGPT倾向于生成幻觉,即不相关的信息后跟翻译模式,影响了MT的表现。使用后处理方法从生成的文本中删除无关信息。
结果:降低温度设定可以减少幻觉的数量,而TSP方法进一步有助于减少幻觉,表明其在提高ChatGPT作为机器翻译系统的作用方面具有潜力。罗马尼亚⇔汉语的完整结果见表3。尽管在这种情况下,TSP方法仅稍微改善了ChatGPT的表现,但这可能归因于理解和生成这些特定语言对的困难。自然语言处理/机器翻译社区应注意在使用ChatGPT进行非英文文本时产生潜在幻觉的问题。
基于这些发现,ChatGPT与TSP的组合被采纳为后续实验的默认设置。
3. 领域特定提示
领域特定信息对机器翻译任务中ChatGPT的性能有重大影响。为了利用这个潜力,引入了领域特定提示(DSP)的概念,旨在为ChatGPT在翻译过程中提供领域特定的指导。其目标是提高ChatGPT的泛化能力,并缩小与像Google翻译这样的高级商业系统之间的性能差距。
DSP方法涉及加入提示,以识别被翻译句子的领域信息。例如,提示可能包含标签,如[DOM]表示正确的领域(例如新闻、生物医学),或者[FDOM]表示错误的领域。通过在提示中引入领域特定的信息,ChatGPT可以更好地适应不同领域的特定要求和特征,并保持HTML结构不变。
为了评估DSP的有效性,我们在具有领域偏见的WMT19生物和新闻数据集上进行了实验。结果显示,如表5所示,原始的ChatGPT在COMET得分和词汇度量(如BLEU)方面表现不及Google翻译。但是,DSP方法始终提高了ChatGPT的性能,甚至在某些数据集(例如WMT19生物中文⇒英文和WMT19新闻英文⇒中文)中胜过了Google翻译。

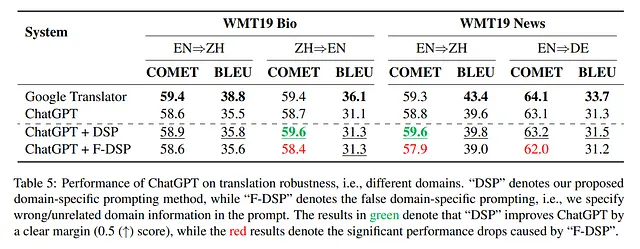
发现突出了DSP方法提高ChatGPT的泛化能力和弥合与先进商业系统之间性能差距的能力。然而,对于BLEU指标的影响仍不一致,而在这方面,ChatGPT仍然显著落后于谷歌翻译的性能。
为了验证域信息在观察到的改进中的作用,进行了一个有意的实验,使用错误的域信息,称为 F-DSP。这有助于挑战 DSP 策略所取得的改进。表 5 的最后一行所描绘的结果清楚地表明,当提供错误的域指导信息(F-DSP)时,COMET 得分持续下降。这证实了在有效地利用 ChatGPT 进行机器翻译任务时,域特定提示指导的重要性。
4. 少量提示
少样本上下文学习在各种自然语言处理任务中展现出的显著能力被研究以进一步了解ChatGPT的潜力。进行的实验涉及不同的样本选择策略。使用Flores-200数据集,评估了很少样本机器翻译的性能,分别在三个翻译方向:英语⇒中文、英语⇒罗马尼亚语、英语⇒德语。实验主要使用从开发集中随机抽样的演示,考虑1-shot和3-shot设置。
实验结果见表6。观察结果表明,在上下文学习中,与零样本方法相比,随机示例持续提高了词汇度量(BLEU)和COMET得分的表现。这一发现与以前的研究结论一致(Hendy等,2023年)。此外,值得注意的是,1-shot方法产生了不错的结果,而进一步增加尝试次数并未带来任何改进。
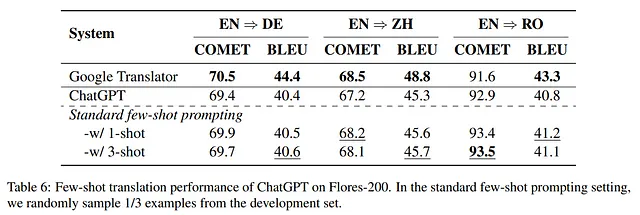
令人鼓舞的是,研究发现,在机器翻译任务的上下文学习中,先进的样本选择策略与基于实例的机器翻译(EBMT)的设计哲学密切相关。EBMT在运行时依赖于双语语料库作为其主要知识库。这一观察结果表明,未来的工作中可以通过借鉴基于实例的机器翻译领域所获得的知识,设计更好的受EBMT启发的ICL策略。
5. 心灵之链 (CoT)
思维链(CoT)提示是一种已经显示出潜力的技术,可以引出大型语言模型的推理能力。虽然先前的研究已经证明了CoT在改善ChatGPT在自然语言理解任务中的表现方面的有效性,但它对机器翻译任务的影响仍然很少被探索。

为了研究CoT对机器翻译的影响,这项研究从测试集中随机选择了20个样本,并采用了零射和1射CoT技术。在零射CoT方法中,使用提示语“请逐步提供以下句子的[TGT]翻译”,以提取逐步翻译。此外,附加句子“然后提供完整的句子:”以确保生成完整的翻译。对于1射CoT,提供了受零射CoT启发的手动中间推理步骤。
实验结果表明,英语⇒德语和英语⇒中文翻译方向的实验结果已在表8中呈现。观察到在零点翻译(zero-shot)的CoT设置下,COMET分数明显下降,尤其是在英语⇒中文翻译中,下降了8.8个COMET点。1-shot CoT提示始终表现优于零点CoT,但在COMET分数方面仍落后于零点提示。

使用不同提示生成的句子进行分析后,发现了有趣的观察结果。使用CoT提示会导致逐字逐句的翻译行为,这被认为是翻译质量显著降低的主要原因。
未来工作
未来的探索将专注于开发不同的CoT变体,这些变体受到统计机器翻译原则的启发。这些变体可能涉及逐字翻译并进行后续排序,短语对短语的翻译并重新排序,以及结构对结构的翻译,等等。目标是完善CoT技术并提高其在增强机器翻译性能方面的效果。
与我联系:https://www.linkedin.com/in/yash-bhaskar/ 更多类似文章:https://medium.com/@yash9439








