探究向量数据库:AI驱动应用的引擎

介绍:
在过去几个月里,向量数据库初创企业在科技行业掀起了风暴,吸引了投资者和爱好者的关注。Weeviate获得了惊人的1600万美元的系列融资,而Pinecone DB以高达2.8亿美元的估值创造了新的高峰。最近,一个只有1.2k GitHub星的谦虚的开源项目Chroma,成功地筹集了1800万美元。这些财务胜利引出了一个问题:什么是向量数据库,为什么它们引起了如此大的轰动?跟随我们一起探索这些卓越数据库背后的秘密以及它们在人工智能驱动的应用中的关键作用。
什么是向量数据库?
在揭开关于向量数据库的神秘面纱之前,让我们从基础知识入手。从本质上来说,向量只是一组数字数组。然而,真正的魔力在于它们能够在连续的高维空间中表示复杂对象,如单词、句子、图片或音频文件,这个空间被称为嵌入空间。这就像参加聚会,志同道合的人自然地聚在一起。同样,嵌入空间将相似的对象分组,映射单词的语义含义,或在不同数据类型中捕捉相似特征。这些强大的嵌入在推荐系统、搜索引擎甚至文本生成工具如Chat GPT中找到了它们的实用性。
存储和查询嵌入:
一旦我们拥有了这些宝贵的嵌入,挑战便出现了:我们如何高效地存储和查询它们?向我们的故事中的英雄——向量数据库走来。虽然像PostgreSQL这样的关系数据库和像Redis这样的文档数据库都对向量提供了一些支持,但新一代的本机向量数据库已经崭露头角。象Weeviate和Milvis这样的开源选择都是用Go编写的,因其多功能性和性能而备受关注。虽然Pinecone不是开源的,但它在业界非常受欢迎。还有就是Chroma,这是一个基于Clickhouse基础上建立的值得关注的项目,受到了开发人员们的广泛关注。这些向量数据库使开发人员能够基于相似度聚类数字数组,从而实现闪电般快速、低延迟的查询。对于由AI驱动的应用程序而言,这使它们成为理想的选择。

矢量数据库和人工智能驱动的应用程序:
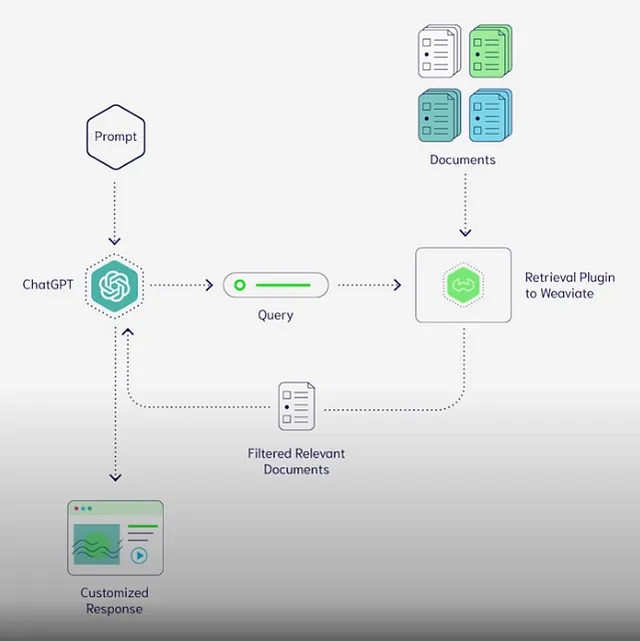
当前对向量数据库的热烈关注源于它们独特的能力,能够扩展大型语言模型(LLMs)的长期记忆能力。想象一下,从像OpenAI的GPT-4或Google的Lambda这样的强大的通用模型开始,然后将自己的数据注入向量数据库。当用户与模型交互时,您可以迅速从数据库中查询相关文档,丰富上下文并自定义响应。此外,向量数据库还提供了检索历史数据的有趣可能性,为AI模型提供长期记忆。这些数据库与链式链接等工具无缝集成,实现多个LLM的组合,解锁前所未有的潜力。
结论:
总之,向量数据库是AI应用新时代的先锋。凭借其通过嵌入式高效存储和查询复杂数据的能力,它已成为推荐系统、搜索引擎和语言模型等领域不可或缺的资产。最近的投资基金激增和创新的Vector Database初创企业的出现进一步展示了它们的潜力,并吸引了科技行业的想象力。随着领域的不断发展,我们热切期待更多的开创性解决方案和应用程序的出现,这将推动AI驱动技术的界限,永久地改变我们与数字世界互动的方式。






