揭示逆戟鲸:微软AI的130亿参数模型

这些模型可以自主监督其行为或其他模型,并进行最少的人类干预吗?
一场革命性的步伐正在人工智能领域的中心发生,模型中的每一个微小的调整都可能意味着重大的进步。微软研究小组推出了Orca,这是一个由GPT-4衍生出的包含130亿参数的模型,通过大型基础模型(LFMs)和阶段性逻辑来增强性能。这种突破性的方法显著提高了模型的性能,解决了任务多样性、复杂查询和大规模数据处理等极具挑战性的问题。
AI模型进展迅速。
虎鲸的影响力超越了改善学习模型;它正在改造人工智能研究过程的本质。虎鲸具有非凡的能力,可以解密复杂的解释追踪信息,并生成丰富多样的训练集,是强大的人工智能学习工具。它促进人工智能学习过程的效率和准确性,为机器学习设定了新的标准。
鲸鱼(Orca)与大型基础模型的未来
透过先进的 AI 学习机制,鲸鱼为 LFMs 带来了巨大的潜力。它为这些模型提供了更好的推理和理解能力,弥补了 AI 中教师和学生之间的差距。初步结果显示鲸鱼具有鼓舞人心的成果,高光了现有模型如 Vicuna-13B,而 BBH 上则显示了超过100%的改善。
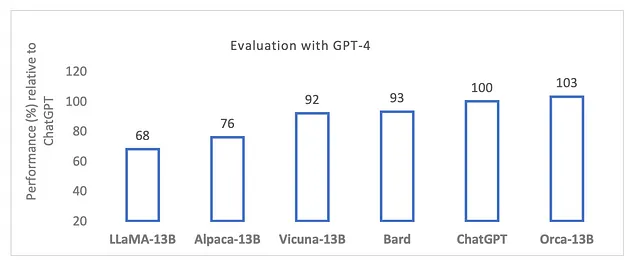
应对挑战:人工智能学习之路
然而,像虎鲸这样的高级AI模型的崛起也面临挑战。一个紧迫的问题困扰着人们:如何利用这些AI模型从复杂的解释痕迹中学习,扩大任务规模,同时最小化人类干预?
让我们开启讨论
让我们一起深入探讨这些关键问题。我们邀请您加入我们,探索逆戟鲸对LFMs和AI领域的影响。我们渴望了解您的观点和见解。请在评论区或社交媒体上分享他们。
让我们揭开这一转型的复杂性,引导这场基于人工智能驱动的大型基础模型革命的方向,至少在2023年6月15日的这个星期四如此,即便AI的未来已经存在一段时间了。您准备好了解ML模型了吗?
- 使用标签 #AITransformation,#technology,#ThursdayThoughts,#Microsoft,#Orca 和 #AIEvolution,加入这个充满激情的旅程。
参与此帖以促进讨论。







