了解稳定扩散生成AI的基础知识

想象这样的场景:昨晚,你梦见自己被送到了一个奇幻世界。古老的王国,雄伟的城堡,神话般的巨龙,迷人的仙女和用美味巧克力制成的山脉包围着你。你的心在这个令人叹为观止的景色中翩翩起舞!
但是唉,醒来后记忆消失了,留下你渴望某种方式来捕捉它。
决心重拾当初的感觉,你打开电脑,希望能找到由才华横溢的艺术家们创作的图片,来保留你的回忆(因为说实话,我的画并不好!)。但是遗憾的是,你偶然看到的那些图片不够好,也不符合你的想象。
在绝望的深处,一个低声的秘密传到了你的耳朵——一种能让你衰落的梦幻世界重获新生的启示。你发现了一款令人难以置信的人工智能生成工具,叫做“稳定扩散”。充满新希望的你决定把思想写下来,就像魔法一样,每个你书写下来的单词都变成了这个美丽的作品——

什么是稳定扩散?
稳定扩散生成人工智能(SD-GAI)是一种尖端技术,利用扩散过程和生成模型的原理生成逼真和高质量的数据。
那太难了吗... 让我给您一个更简单的解释 -
稳定扩散AI是一种先进的技术,可以根据用户的文本输入生成所需的图像。
是的,这意味着现在可以通过稳定的扩散模型从简单的文本指令创建图像。
无论你想要一张尼尔·阿姆斯特朗骑马在月球上的照片还是一张灭霸在当地沃尔玛商场购物的照片,你都可以创造出这样的形象,即使它并不真实或只是你的狂想。

我们应该感谢谁给予我们如此惊人的恩赐呢?
CompVis、Stability AI 和 LAION 的研究人员和工程师联合开发了一款印象深刻的文本到图像的潜在扩散模型,名为 Stable Diffusion。该模型经过训练,使用了 LAION-5B 数据库的一个子集,特别关注 512x512 的图像。值得注意的是,LAION-5B 拥有目前最广泛的免费多模态数据集的称号,为各种应用提供了丰富多样的信息。
稳定扩散的工作原理是什么?
使用稳定的扩散技术,一切都变得轻而易举。是的,这是一个强大的深度学习模型,可以将文本转换成图像。
但作为像你和我这样的开发者和编码人员,我们必须有一种诀窍,知道稳定扩散实际上是如何工作的。另外,理解其基本原理将大大提高您使用这项技术的熟练程度。
注意:我会尽可能简化解释,让您理解并集中精力在加深理解的关键方面。这项技术非常复杂,需要深入的知识,类似于博士水平的理解。所以,暂时我不会涉及数学。这肯定会让你现在微笑,哈哈哈。
稳定扩散的基础原理
每天在互联网上浏览时,我们会遇到几个图像标题,比如博客或文章中的标题。通常,我们 tend to 忽略它们。全球有数十亿这样的图像可供使用,它们具有相当好的质量,并且在互联网上以良好的准确性进行描述,是图像生成模型的训练数据的主要组成部分。
为了从文本生成图像,我们首先要“训练”一个机器学习模型。这个模型是使用大量图像及其相关的文本描述进行训练的。
基本上我们告诉模型,这张图片表示这个这个之类的东西。就像教一个婴儿手中的圆形物体是球一样。通过这个训练数据,模型获得了对描述中的词语和图像中可见的属性之间关系的理解。
简单来说,我们提供数十亿张图片,并指示计算机识别每张图片的内容,使其能够有效地理解这些不同对象是什么。
一旦我们传授了将文本描述中的连接词与其相应的图像联系起来的知识,该模型利用深度学习来独立识别它们之间的关系。深度学习涉及构建具有相互连接的“神经元”分层组织的神经网络。这些网络分析广泛的数据集来解决复杂任务,如将文本与图像相关联。
意味着你的人工智能现在能够根据新的文本描述建立与已经训练的图像不同但相关的新图像。
然而,值得注意的是,这个方面并不是特别新颖的,因为这项技术已经存在了一段时间,而且结果并不高质量。

稳定扩散是魔法开始的地方。
你和我都知道,计算机只能理解1和0的语言。它缺乏感知图像或文字的内在能力。
就像我们的视觉系统一样,当我们观察某样东西时,图像中的光线会到达我们的眼睛,并通过视网膜转化为电信号。这些信号随后被我们的大脑解读,使我们能够识别和理解我们所感知的物体。
同样地,电脑需要做类似的事情才能理解图像。我们为什么不讨论这个逻辑,我相信你会惊讶地看到如何无缝地将所有东西组合在一起!所以,别再闲逛了,让我们一一看清楚。
计算机使用字典分配数字值给单词部分,称为文本嵌入。通过将单词或图像表示为数值向量,我们可以利用这些向量作为机器学习算法的输入。这些算法随后从数据中学习,并能基于所获得的知识进行预测或生成新数据。
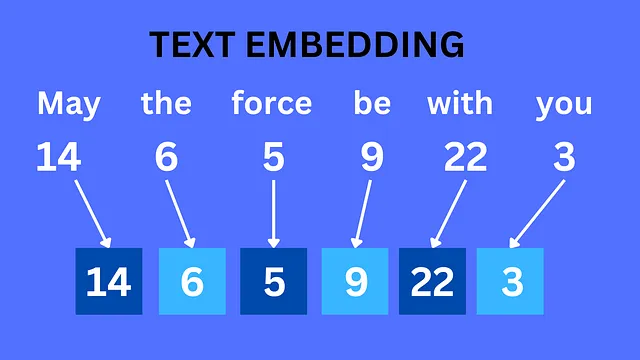
上面的图片展示了文本嵌入的工作原理。图像嵌入的过程略有不同,因为涉及到一些额外的步骤。
最初,图像通过卷积神经网络(CNN)处理,这是一种专门设计用于自动识别图像中显著特征和模式的深度学习模型。通过这个过程,图像的独特特征被表示为数字向量,使得可以对它们进行数学运算。
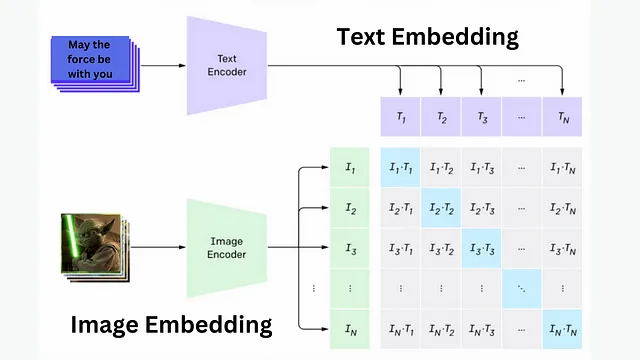
现在,我们具有文本嵌入和图像嵌入,它们本质上是图像及其相应标题的数值表示。
这便是CLIP(对比语言-图像预训练)的魔力所在。 它的主要作用是获取这两个嵌入并确定它们的相似之处。通过利用CLIP,我们能够获得非常清晰和逼真的结果。
什么是CLIP?
CLIP是一种开源模型,旨在评估图像标题的质量。虽然模型本身是免费可用的,但关键是需要注意,用于训练CLIP的数据集并不是公开的。
想要看到这一切的实际运作吗?请点击链接:https://huggingface.co/spaces/EleutherAI/clip-guided-diffusion
In Chinese: 稳定扩散中的扩散
想象一下,你遇到了各种圆形物体,需要仅凭视觉观察来区分足球和保龄球。你会如何区分它们?答案很显然:你可以通过它们的外观轻易地区分它们。没错!
但是,如何让计算机做同样的事情呢?现在,这是一个很困难的问题。实际上,答案已经在你的脑海中了,我指的是字面上的你的脑海中!
你可能从未意识到,在你我心中,至少存在三个清晰的“轴”,帮助我们对物体进行分类。一个是形状,另一个对应颜色,也许还有一个是大小。足球在这个心理图表上占据了一个特定的位置,而网球则完全位于不同的位置。
稳定扩散采用类似的原理,但维度和变量数量明显更大。在这种情况下,我们的人类认知能力不够,因为我们很难想象超过三个维度。然而,我们的模型超越了这种限制,在由超过500个维度和大量变量组成的潜在空间中运作。
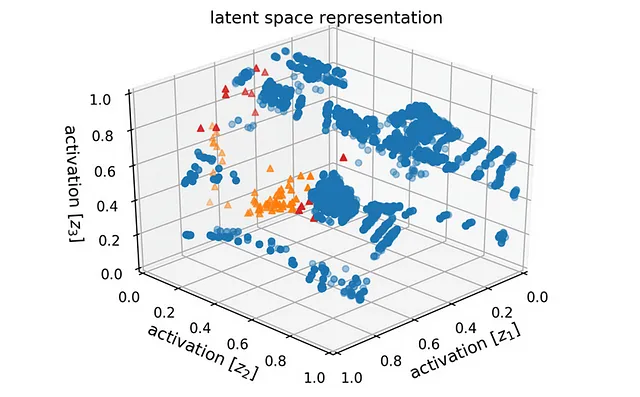
使用稳定扩散来从文本生成狗狗图片
让我们考虑一个场景,你正在训练一种机器学习模型,以基于文本描述生成狗狗图片。在这个上下文中,潜在空间代表一个多维空间,每个点都对应一个独特的狗狗图片。
如果您将一只毛茸茸的黑狗的描述输入到这个潜空间中,模型将通过空间穿行并找到可能代表黑色猎狗的那个点。使用此点作为起始参考,模型将生成一个与输入描述密切相关的新狗狗图片。
这种卓越的能力也突显了我们提示的强大之处,因为它们在我们的人类想象之外的维度中运行。有效地使用文本导航这个空间需要众多的数学坐标。因此,通过增加附加修饰语,我们提高了我们结果的质量。
穿越这个空间并识别与给定输入相连接的点的过程称为扩散。
一旦最接近的文本提示点被识别出来,模型就会运用更多的AI技术来完成其魔力并生成输出图像,即一只黑色蓬松的狗。

完美!您现在已经掌握了稳定扩散的基本知识。如果您感到兴趣并渴望进一步深入研究这个主题,我建议查看稳定扩散的官方文档,了解其各个组件的全面解释。
你最初可能会质疑理解这一切的价值。然而,拥有这种理解,你将拥有构建超越他人想象的非凡创造物的能力。
开源模型如Stable Diffusion革命性地允许与其他技术进行微调和集成,以产生高度精确的描述。
你刚学到的东西将会复合并帮助你构建你以前无法想象的东西 :)
做这个,否则我会伤心 ?
如果您在理解这些内容的任何部分上遇到任何问题,请在评论中提问,我一定会帮助您解决。另外,为什么不直接前往Stable Diffusion并创建您自己的第一张AI生成的图像,并在社交媒体上标记我来查看它。
你刚刚获得的知识将积聚并推动你前往无法想象的目的地。准备好迎接前方惊人的旅程吧!
祝你好运!
希望您喜欢阅读这篇文章。您可以关注我,获取最新资讯,当我发布更多的精彩文章。
此外,该文章是Segmind Generative AI Blogathon的投稿。所以,请支持我赢得这个比赛。
如果您从本文中学到了有价值的东西,请鼓掌并关注我,如果您觉得有帮助。
跟随我,获取更多有助于你面试和学习编码的精彩文章。
我是谁?
只是一个热衷于写自己喜欢的内容的人。科技博客、最新科技新闻、教程、编码问题解决方案、社论、面试技巧等等,这些你一定会喜欢的东西。
此外,我也为自由职业者撰写文章,如果您有兴趣可以通过下面的链接联系我。
如果您喜欢这篇文章,请通过 Medium 关注我,获取我惊人和有用文章的最新更新,给我支持。
你可以在 https://ko-fi.com/medusaverse 鼓励我写更多。
我很高兴与你连接:https://linktr.ee/harshit_raj_14