#Chatgpt #AI #gpt…:社交媒体平台如何处理标签

在我的上一篇帖子中,我简要介绍了索引。现在是实施一些东西并检查一些真实例子实际工作的时候了。我们的主要示例将深入研究流行社交媒体平台上标签的工作原理。为了增加一些乐趣,我们将使用流行的标签,比如#Chatgpt #AI等等。虽然具体的实现方式可能对于所有平台来说并不相同,但是底层概念通常是通过索引实现的。
我更熟悉PostgreSQL,因此本系列文章中将一直使用它。
型号:
#tags.py
class Tag():
id = Column(Integer, primary_key=True)
name = Column(String) #tags will be stored here.等等……为什么名字上没有唯一约束?因为……
唯一约束本身就是唯一索引。
是的,在幕后,大多数sql平台将唯一约束实现为唯一索引。请查看Postgres文档。
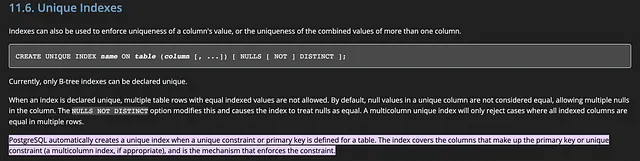
继续前进… 不添加唯一约束的原因是我们可以将结果进行比较,以了解是否需要进行索引。
言归正传:
我已经创建了大约一百万个独特的标签。
postgres=# select count(*) from tags;
count
---------
1105568
(1 row)如果我们查询一个标签而没有任何索引,会出现什么结果?
postgres=# explain analyze select * from tags where name = '#chatgpt';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..14835.27 rows=1 width=27) (actual time=56.066..58.581 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on tags (cost=0.00..13835.17 rows=1 width=27) (actual time=27.404..27.404 rows=0 loops=3)
Filter: ((name)::text = '#chatgpt'::text)
Rows Removed by Filter: 368530
Planning Time: 0.125 ms
Execution Time: 58.608 ms
(8 rows)由于没有其他选择,Postgres直接进行了顺序扫描。
添加索引(唯一约束)后再查看。
postgres=# explain analyze select * from tags where name = '#chatgpt';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Index Scan using "Unique Tag" on tags (cost=0.43..8.45 rows=1 width=27) (actual time=0.121..0.126 rows=1 loops=1)
Index Cond: ((name)::text = '#chatgpt'::text)
Planning Time: 0.212 ms
Execution Time: 0.173 ms
(4 rows)与之前的查询相比,这次Postgres使用了索引扫描,因为我们添加了唯一约束。
如果我们四舍五入数值,则从59毫秒到1毫秒,约为98.31%的改善。
什么是权衡?
在我之前的文章中,我提到为了获得更好的性能,通常我们会在时间上进行空间的交换。这次我们交换了多少空间呢?

47 MB对于1百万个标签和98%的改进来说还不错。我认为我们在这里做得不错。然而,随着标签的增加,空间将会增加。
接下来是什么?
可以快速找到标签,我们就能获取与其相关的文章。通常情况下有三个模型。
class Tag(Base):
__tablename__ = 'tags'
id = Column(Integer, primary_key=True)
name = Column(String, unique=True)
def __repr__(self):
return f"Tag(id={self.id}, name='{self.name}')"
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
content = Column(String)
def __repr__(self):
return f"Post(id={self.id}, content='{self.content}')"
class PostTag(Base):
__tablename__ = 'post_tags'
id = Column(Integer, primary_key=True)
post_id = Column(Integer, ForeignKey('posts.id')))
tag_id = Column(Integer, ForeignKey('tags.id'))
def __repr__(self):
return f"PostTag(post_id={self.post_id}, tag_id={self.tag_id})"这就是吗?
当然不是,我们只尝试过一百万个标签。像 Instagram、LinkedIn 这样的真实平台拥有数十亿的活跃用户。一百万对于它们来说仅仅是最低限度。此外还有许多技术应用于其上:缓存、分片和分区(水平扩展)。
同时,并非所有公司都遵循这种情况,因此为避免过度设计,索引是一个很好的起点。