提示插件的能力:我们可以通过ChatGPT解决泰坦尼克挑战吗?
加速您的数据科学并避免坑的有力助手
TL;DR(简而言之)
Noteable的ChatGPT插件绝对是您的良伴。它允许数据科学家和分析人员交互式地快速执行EDA、特征工程和建模任务。只需通过聊天发送几个指令,我们就可以轻松解决泰坦尼克号挑战。
然而,我们必须注意可能存在的错误。如果错误发生了,ChatGPT会尝试自动修复代码。当发生这种情况时,这是需要我们仔细检查代码的警示信号。
1. 介绍
虽然 ChatGPT 是一种创新工具,但默认情况下不支持数据的导入/导出功能,使其在数据科学和数据分析中的使用变得困难。
然而,自2023年3月宣布ChatGPT插件以来,一系列插件已经推出。引人注目的是提升ChatGPT数据分析能力的插件,它正在日益受到关注。
在本文中,我将使用著名的Kaggle Titanic数据集展示其优点和缺点。
2. Noteable的ChatGPT插件是什么?
值得注意的是,Noteable是一项协作式的数据笔记本服务,允许您结合编码(SQL、Python 和 R)与交互式可视化展示。简单地说,它类似于Jupyter笔记本和Google Colab。
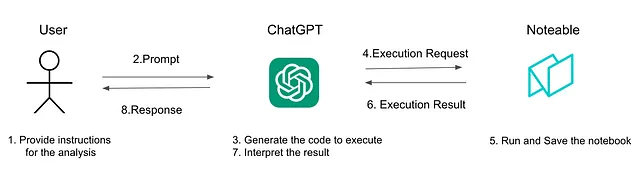
以下图像显示了 ChatGPT 和 Noteable 所扮演的角色。Noteable 充当笔记本和执行环境,而 ChatGPT 则作为“大脑”,确定要执行的代码。用户通常与 ChatGPT 交互,但他们也可以直接访问 Noteable,以查看、编辑和下载生成的笔记本。
4. 如何设置Noteable
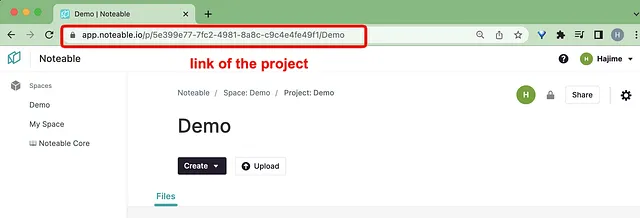
在开始之前,请先创建一个Noteable账户和一个项目(免费的)。然后,我们需要登录ChatGPT并激活Noteable插件。如果你不熟悉ChatGPT插件,请参考下面的视频指导。这个设置只需要不到5分钟。
5. 通过Noteable插件解决Kaggle泰坦尼克号挑战的指南
在这个部分,我将通过仅使用提示来引导您应对泰坦尼克挑战。正如您可能已经知道的那样,泰坦尼克竞赛旨在使用各种信息(例如年龄,性别和车票等级)来预测1912年不幸航行中乘客的生存。
如果您想查看完整的聊天记录,可以点击这里。如果您对查看值得注意的笔记本感兴趣,请点击这里。
第一步:数据导入
我们的第一步是指定Noteable项目的链接和要导入的数据集。这是使用的提示。
提示:让我们使用这个项目: > 加载这个数据: https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv
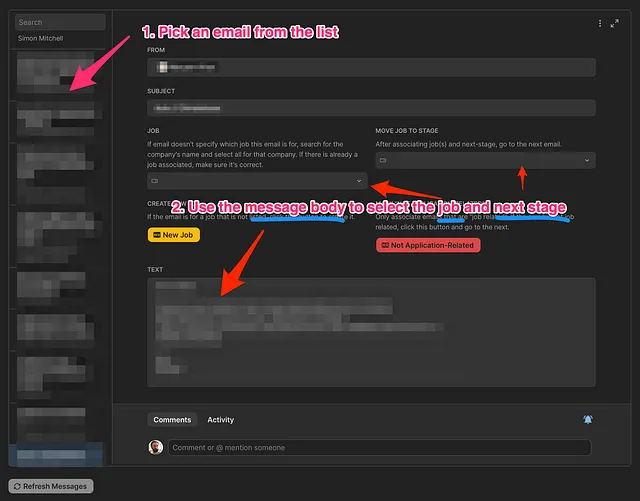
您可以通过登录Noteable网站并选择项目来找到您的>。
根据给定提示,ChatGPT要求Noteable导入数据并预览前5行数据。
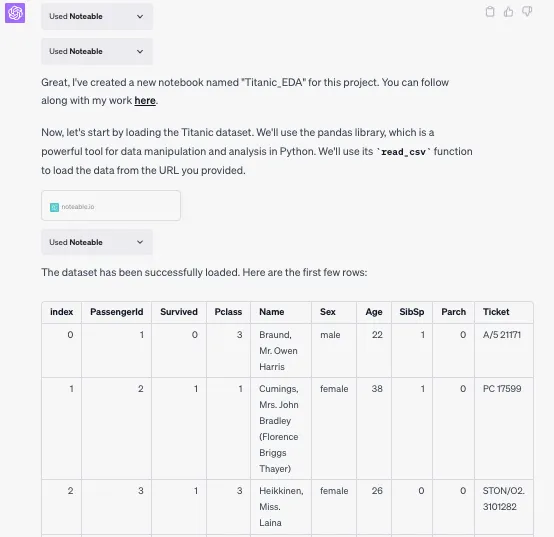
你可以看到ChatGPT输出了“Used Noteable”。此时,下面的Python代码正在Noteable上执行。
import pandas as pd
# URL of the Titanic dataset
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
# Load the data
df = pd.read_csv(url)
# Display the first few rows of the dataframe
df.head()步骤 2. 探索性数据分析(EDA)
就像任何典型的数据项目一样,让我们首先了解每个数据元素的特征。我们可以使用以下提示进行初步分析。
提示:我计划对“泰坦尼克”数据集执行探索性数据分析,其中包含有关乘客的信息,包括他们是否生存。我旨在回答以下问题:- 有多少乘客幸存了?- 哪些类型的人有更高的生存机会? 我计划对“泰坦尼克”数据集执行探索性数据分析,该数据集包含有关乘客的信息,包括他们是否生存。我旨在回答以下问题:- 有多少乘客幸存了?- 哪些类型的人有更高的生存机会?
请在笔记本里包含说明文字,以简单易懂的方式向我解释你正在做什么以及为什么这很重要。
回应此提示,将阐明乘客阶级与他们的生存率之间的关系。
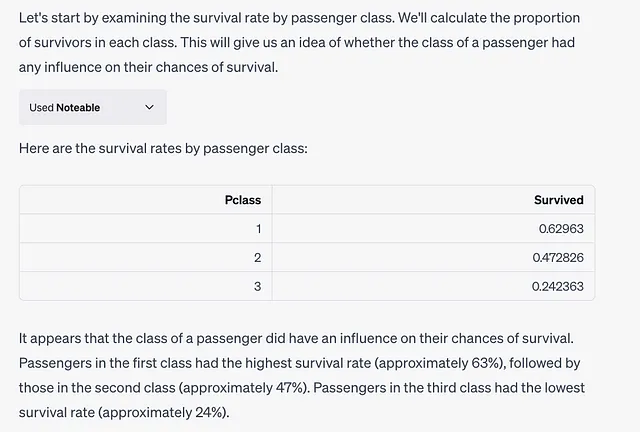
在此交互过程中,ChatGPT向Noteable发送请求,并执行以下代码: df.groupby('Pclass')['Survived'].mean()
步骤3. 特征工程
在整个EDA过程中,我们注意到ChatGPT会对聚合结果进行特征工程,即使没有特定的人类指令。
举例来说,当分析“年龄”列时,会创建一个新的“年龄组”列,将年龄分成“儿童”和“青少年”等分组。下表显示年龄组显着影响生存率,“儿童”拥有最高的生存概率。
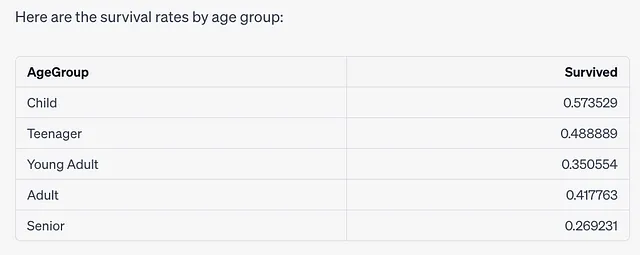
ChatGPT 发送请求到 Noteable 并执行以下代码。
# Define age groups
bins = [0, 12, 18, 30, 60, 100]
labels = ['Child', 'Teenager', 'Young Adult', 'Adult', 'Senior']
df['AgeGroup'] = pd.cut(df['Age'], bins=bins, labels=labels, right=False)
# Calculate the survival rate by age group
survival_rate_by_age_group = df.groupby('AgeGroup')['Survived'].mean()
survival_rate_by_age_group也可以请求文本处理。
让我们以“姓名”字段为例。 “姓名”列包含混合在一起的姓名和头衔(先生,夫人,小姐等),例如“布朗德,欧文·哈里斯先生”和“海基宁,莱娜小姐”。
提示:请分析乘客姓名中是否有独特特征。然后利用这些信息进行特征工程,添加更多有意义的变量。
为了回应这个问题,ChatGPT从每个姓名中提取标题,因为它可能提供有关乘客性别、婚姻状况和社会地位的信息,所有这些可能与他们的生存机会有关。
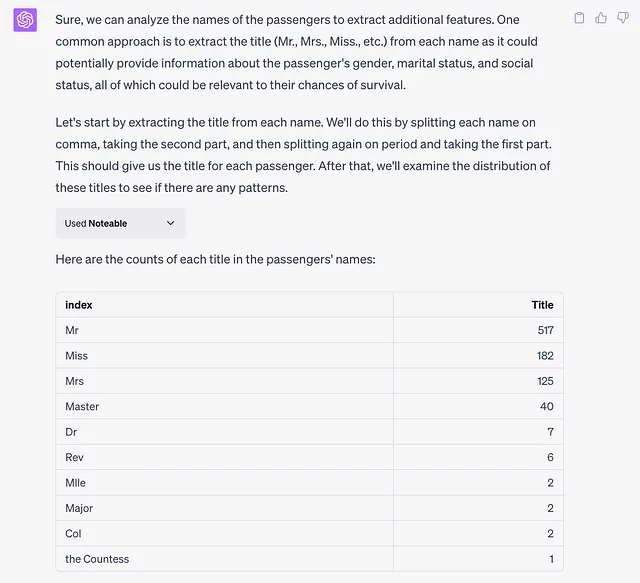
在笔记本中,名字是由空格分隔开的,然后提取标题部分。
# Extract the title from each name
df['Title'] = df['Name'].apply(lambda name: name.split(',')[1].split('.')[0].strip())
# Count the number of occurrences of each title
title_counts = df['Title'].value_counts()
title_countspp大多数乘客的称谓是“先生”、“小姐”、“太太”或“小姐”,由于还有很多很少出现的称谓,ChatGPT将它们归为一个“其他”类别,以避免创建过多的分类。
# Define a list of common titles
common_titles = ['Mr', 'Miss', 'Mrs', 'Master']
# Group rare titles under 'Other'
df['Title'] = df['Title'].apply(lambda title: title if title in common_titles else 'Other')
# Calculate the survival rate by title
survival_rate_by_title = df.groupby('Title')['Survived'].mean()
survival_rate_by_title以下是将罕见职称分组为“其他”后的职称生存率。
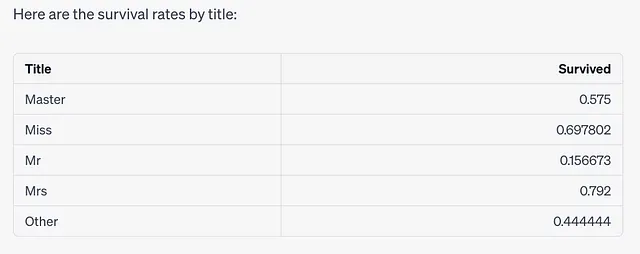
事实证明,使用“女士”或“小姐”称谓的人具有更高的生存率,而使用“先生”称谓的人则具有较低的生存率。
第四步。处理缺失值:
通常,在建模之前需要解决缺失值问题。让我们接下来来解决这个问题。
提示:请进行分析以确定任何缺失的数据。然后,如果一列包含缺失值,请以最有效的方式处理它们。
遵循此指令,ChatGPT首先确定我们的数据集中哪些列包含缺失值:df.isnull().sum()
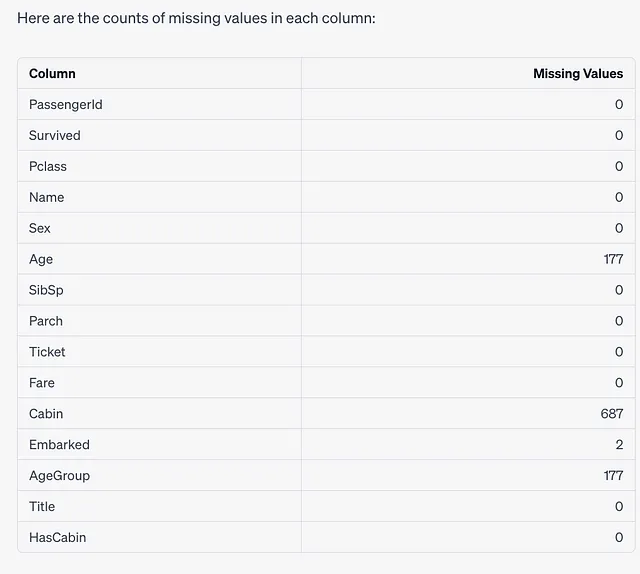
“Age”、“Cabin”、“Agegroup” 和 “Embarked” 列包含缺失值。
基于缺失值的百分比,ChatGPT决定如何处理这些间隙,例如,通过中位数值填充“年龄”和“登船港口”列,以及创建一个新列“HasCabin”,以指示是否存在“Cabin”信息,鉴于缺失值的丰富性。
# Fill missing 'Age' values with the median age
df['Age'].fillna(df['Age'].median(), inplace=True)
# Fill missing 'Embarked' values with the most common port of embarkation
most_common_port = df['Embarked'].mode()[0]
df['Embarked'].fillna(most_common_port, inplace=True)
# Create a new feature that indicates whether a cabin value is present or not
df['HasCabin'] = df['Cabin'].apply(lambda cabin: 0 if pd.isnull(cabin) else 1)
# Drop the 'Cabin' column
df.drop('Cabin', axis=1, inplace=True)第五步:预测
接下来,让我们建立一个模型来预测生存。
提示:请建立一个预测生存的模型。请注意,您需要将数据分成训练集和测试集。选择您认为最好的建模方法。请解释您选择建模方法的原因。
ChatGPT会选择什么建模方法?
ChatGPT选择随机森林分类器。然后使用独热编码处理分类变量,并使用scikit-learn训练模型。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
# Select the columns to use for prediction
predictor_columns = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'Title', 'HasCabin']
# Select the target variable
target_column = 'Survived'
# Prepare the predictors
X = df[predictor_columns]
# One-hot encode categorical variables
X = pd.get_dummies(X)
# Prepare the target
y = df[target_column]
# Split the data into a training set and a testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Check the shapes of the datasets
X_train.shape, X_test.shape, y_train.shape, y_test.shape
from sklearn.ensemble import RandomForestClassifier
# Initialize a random forest classifier
clf = RandomForestClassifier(random_state=42)
# Train the classifier on the training data
clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
# Make predictions on the testing data
y_pred = clf.predict(X_test)
# Calculate the accuracy of the predictions
accuracy = accuracy_score(y_test, y_pred)
accuracy这个随机森林分类器在测试数据上达到了约82.1%的准确率。
第六步。解读模型。
该模型可以定性地解释,方法是对每个变量的重要性进行排序。
提示:您能向我展示每个因素的重要性吗?
ChatGPT 使用训练后的随机森林模型的特征重要性属性来了解每个特征在预测生存方面的重要性。
import matplotlib.pyplot as plt
import seaborn as sns
# Get feature importances
importances = clf.feature_importances_
# Convert importances to a DataFrame
importances_df = pd.DataFrame({'feature': X_train.columns, 'importance': importances})
# Sort importances_df by 'importance'
importances_df.sort_values('importance', ascending=False, inplace=True)
# Plot feature importances
plt.figure(figsize=(10, 6))
sns.barplot(x='importance', y='feature', data=importances_df)
plt.title('Feature importances')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()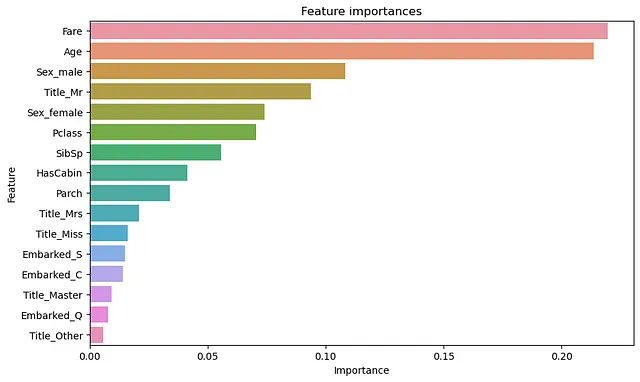
正如你所看到的,根据模型,‘票价’、‘年龄’和‘性别_男性’是预测生存最重要的特征。这与早期的探索性数据分析一致,该分析表明这些因素与生存密切相关。
第七步。预测。
最后,让我们使用测试数据集进行预测并在Kaggle上提交。
提示:您可以使用下面的测试数据集来进行预测吗?https://raw.githubusercontent.com/dsindy/kaggle-titanic/master/data/test.csv
在对测试数据进行预测之前,ChatGPT会试图以与训练数据相同的方式对其进行预处理。此预处理包括填充缺失值、创建“标题”和“HasCabin”特征以及对分类变量进行独热编码。
在这里,检测到一个错误。出乎意料的是,ChatGPT一直在尝试纠正代码,并不断生成新代码。
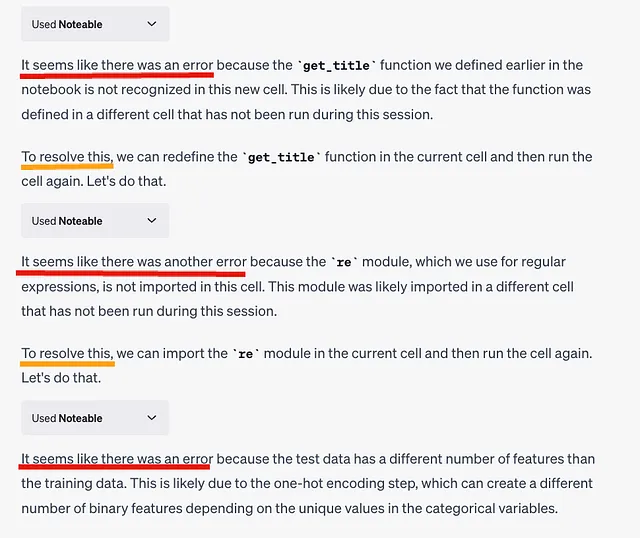
以下是ChatGPT执行的最终代码。
很不幸,转换名称为标题的部分出现了错误 ⚠️。在训练过程中,ChatGPT总是出现如“先生”、“小姐”、“夫人”和“硕士”之类的称呼,并将较少出现的头衔(如“博士”和“牧师”)聚合到“其他”中。然而,此时此刻,ChatGPT并不记得这一点,并将所有头衔都包括在“标题”栏中,包括像“博士”和“牧师”这样的头衔。
# Load the test data
test_data_url = 'https://raw.githubusercontent.com/dsindy/kaggle-titanic/master/data/test.csv'
test_df = pd.read_csv(test_data_url)
import re
# Redefine the get_title function
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
# Fill missing 'Age' values with the median age of the training data
test_df['Age'].fillna(df['Age'].median(), inplace=True)
# Fill missing 'Fare' values with the median fare of the training data
test_df['Fare'].fillna(df['Fare'].median(), inplace=True)
# Extract titles from names
test_df['Title'] = test_df['Name'].apply(get_title)
# Create a 'HasCabin' feature
test_df['HasCabin'] = test_df['Cabin'].apply(lambda cabin: 0 if pd.isnull(cabin) else 1)
# Prepare the predictors
X_test_new = test_df[predictor_columns]
# One-hot encode categorical variables
X_test_new = pd.get_dummies(X_test_new)
# Make predictions on the new test data
predictions = clf.predict(X_test_new)
# Create a DataFrame with the passenger IDs and the predictions
predictions_df = pd.DataFrame({'PassengerId': test_df['PassengerId'], 'Survived': predictions})
# Display the first few rows of the predictions
predictions_df.head()
# Save the predictions to a CSV file
predictions_df.to_csv('predictions.csv', index=False)在将此输出的CSV提交给Kaggle后,得分为0.74。虽然它并不是特别好,但考虑到它是在一个小时内完成的,它作为一个基准非常有用。
6. 结论
个人认为它足以用于快速创建基准分析和模型的起点。特别是对于EDA,ChatGPT x Noteable可能是一个非常强大的工具。只需要通过聊天发送几条指令,我们就可以轻松应对“泰坦尼克号挑战”。
然而,我们需要非常小心潜在的错误或不一致的行为。特别是在复杂的过程中,错误很可能发生。即使发生错误,ChatGPT 也会尝试修改代码以修复该错误并进行重试。当这种情况发生时,这是我们需要仔细查看代码的警告信号。
7. 链接
- ChatGPT 的聊天记录:https://chat.openai.com/share/c18c080e-3055-4156-a763-0755cba9cabe
- 注意事项:此帖子的历史记录为https://app.noteable.io/f/ce333a3a-8ae2-4851-b83b-55d205a577f1/Titanic_EDA.ipynb
- Kaggle: https://www.kaggle.com/c/titanic Kaggle:https://www.kaggle.com/c/titanic
感谢您的阅读!如果您有任何问题/建议,请随时在 Linkedin或Twtter 上联系我!此外,如果您在 Towards Data Science 上关注我,我会很高兴的。