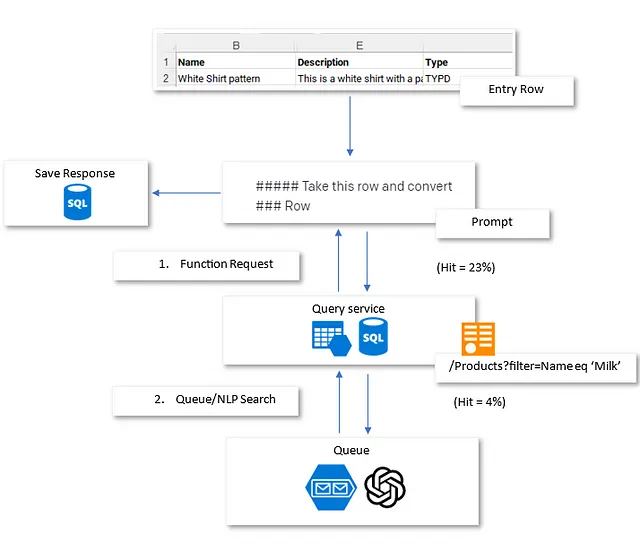
提高人工智能对话:通过CATCH和LVC实现更好的上下文理解之旅

人工智能的世界是一个连续不断创新和探索的复杂舞蹈。就像一个宏大的拼图,每一个我们揭开的拼图都会引导我们得到新的认识,新的视角。然而,有一个拼图一直难以得手,那就是让人工智能真正理解和记忆对话中的语境。这个拼图,正是我最近的研究所致力于解决的问题。
想象一下——你正在和朋友谈论一本你最近读过的书。你们讨论角色、情节和你的观点。第二天,你们继续讨论,从你们停下的地方接着说。你回顾昨天的谈话,谈论你的观点如何改变了,你的朋友都能理解,因为他们记得上下文。这种无缝的过渡、自然的回忆,是我们人类轻松做到的。现在,如果我们的AI助手也能做到同样的事情,那不是很有趣吗?这就是我创建CATCH方法的原因所在。
在我最近的白皮书中,我介绍了一种名为 CATCH 的新方法,这是一个缩写,代表着通过会话超向量建立上下文关联。这种策略与连结向量上下文(LVC)方法相结合,提供了一个激动人心的机会,来推进人工智能对上下文的理解,从而增强它的会话理解能力。
在CATCH方法的核心是将复杂的对话细节转化为高维向量表示。想象一下,能够捕捉对话的本质和细微差别,将它们压缩成紧凑的向量。然后将这些向量系统地存储在向量数据库中,随时可以检索。该过程使得AI模型能够访问上下文相关信息,类似于我们人类在谈话时回忆先前的讨论。
LVC方法通过将对话分段为可管理的部分来增强CATCH方法,就像我们将复杂的问题分解成较小的部分来解决一样。每个部分都被分配其向量等价物并系统地存储在数据库中。从正在进行的对话中提取主要元素并转换为查询向量,这些向量然后与数据库中的匹配向量进行比较。就像从图书馆的书架上取书一样,相关的对话块被检索出来,为AI提供了制定适当响应所需的必要上下文。
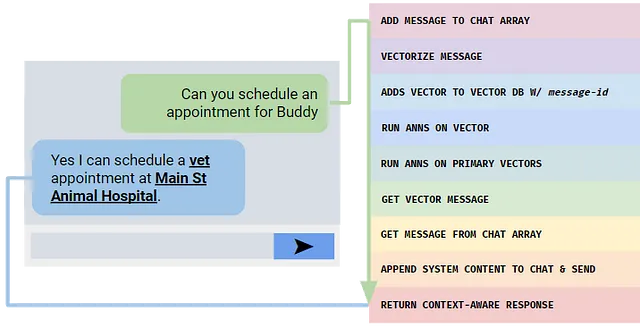
隐私和效率是人工智能技术的两个关键要素,常常在讨论新方法时涉及。您可能会想知道我的方法如何解决这些问题。那么,CATCH方法的美妙之处在于其设计将这些因素置于至高无上的重要性。数据库存储向量,而不是实际的对话内容,从而在向量存储方面保持用户隐私完好无损,同时强大的对话加密保证了上下文检索的安全性。LVC方法进一步增强了这一点,它采用了一种动态机制,根据正在进行的对话的性质调整矢量化和数据库内容,就像人类根据对话的语气和主题调整其回答一样。
然而,旅途并不缺乏挑战。生成高质量的语义向量嵌入对于精确的上下文回忆是必不可少的。优化向量数据库和完善检索策略的任务类似于微调复杂机器。加上这些,计算需求和数据隐私问题,任务的重要性就变得清晰了。
但是,每一朵浓云都有银边,我们可以掌握的潜在解决方案也是如此。类似Bard、BERT、RoBERTa和GPT-4这样的高级语言模型可以帮助提高向量嵌入的质量。近似最近邻(ANN)算法可以潜在地加速数据库检索。高效算法和专业硬件可以强化实时向量化,而差分隐私和加密方法等技术则可以保护用户数据,为存储用户信息提供安全保障。
除了技术解决方案,我的论文强调了与这项工作相关的伦理考虑。我认为,随着我们开拓创新之路,我们必须确保我们负责任地进行。这包括小心处理敏感数据和优先考虑用户同意——我珍视的原则。我已经提出了评估指标和实用方法,以实施和评估CATCH方法和LVC改进,强调这些概念需要超越理论,找到它们在现实世界应用的位置。
简而言之,CATCH方法和LVC增强技术可以显著改变会话AI领域的叙事。它们具有提高上下文理解、增强用户体验和培养对AI系统的信任潜力。虽然面临着挑战,但建议的解决方案和该领域正在取得的显著进展为会话AI的未来描绘出了希望之景。这是我非常兴奋并热切期待与您分享的探索之旅。让我们一起翻开AI故事的下一章。
您可以在GitHub上阅读白皮书,https://github.com/Codable-AI/CATCH/